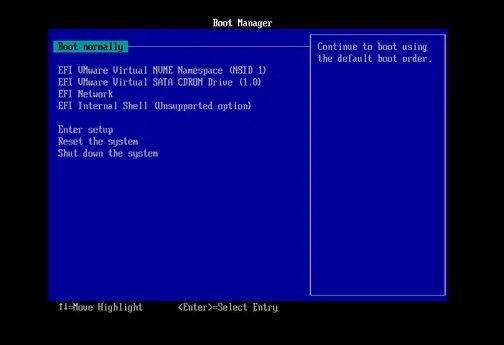
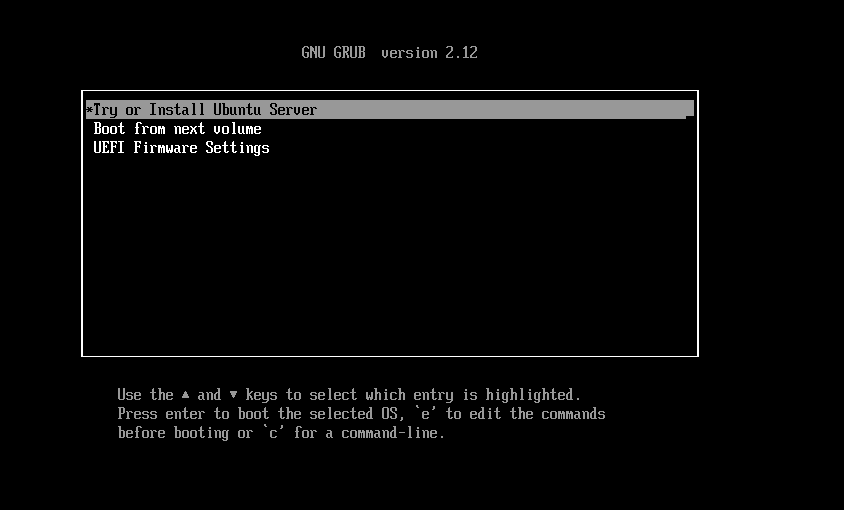
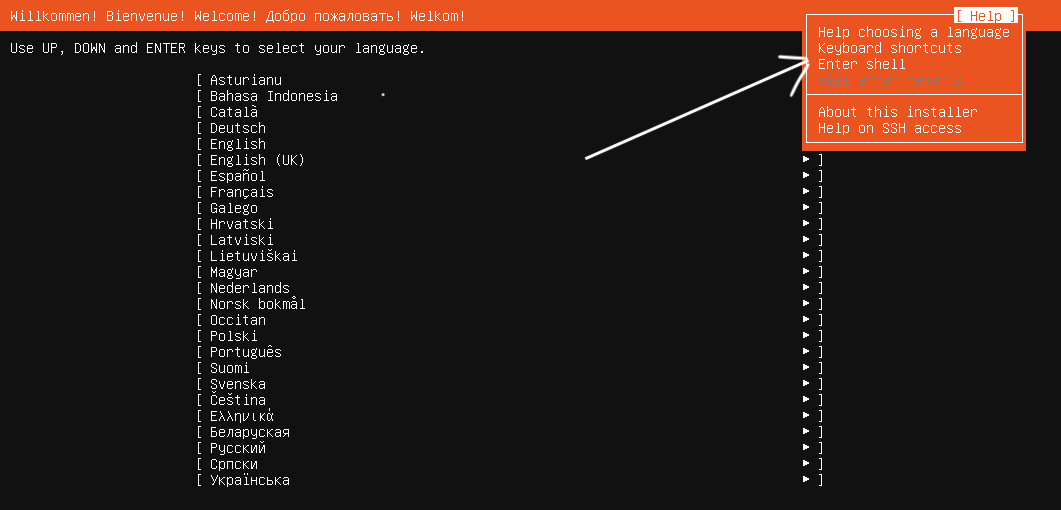
I recently encountered a situation where my Ubuntu 24.04 VM was failing to boot. The blue screen DOS-style Boot Manager would be displayed and booting was halted here, with an implicit ‘you shall not pass’. This post covers how i addressed the problem,
Here is my setup:
Apple MBP M4
VMware Fusion 13.6.3
VM – Ubuntu 24.04 Server ARM
Maybe this article is not for you – here’s a quick summary to help you decide for yourself; create an Ubuntu ARM Server (Server was the only ARM version in Ubuntu town) bootable disk, attach the USB drive to the VM, boot from the USB drive, break out of the Ubuntu Server install and drop to a shell (this was not straightforward – see below), mount the correct /dev devices on /mnt and /mnt/boot/efi, along with dev, proc, etc directories. From here there’s one or both of two deviants who are liikely guilty – GRUB corruption, or kernel corruption. In my case it was GRUB corruption and the fix is below…
The Bootable Disk
This was a very helpful article: Create a bootable USB stick on Ubuntu – this should have got you all the way to a bootable USB drive. The iso to use is of course the ARM server version if you on M1-4 Mac. At the time of writing there is no Ubuntu Desktop 24 for ARM architectures.
Connecting Your USB Drive To Your VM
Having followed the link Create a bootable USB stick on Ubuntu , you will have got your MBP to recognise the USB drive. Boot your VM. You may not see the USB as a selectiable boot drive in the top menu, in which go down to ‘Reset The System’. This worked for me. Boot from the USB drive.
Ubuntu ARM Server install Breakout
You should see the following Grub screen …
There is an option there – ‘Try or Install Ubuntu Server’. The menu is lying to you – do not believe it. There is no ‘try’, there is only install. Unless you find an off-script way to break out. Hit enter for the try/install option and then select the help option in the top right (as below), within which menu there is a shell option …
Mounting Your Ubuntu Drive and Repairing Your GRUB
Entering the shell, you are in a world where you are running a shell of the OS from the USB drive. You are not yet on the planet you want to be on, which is your broken Ubuntu 24 partition.
List your devices
From the shell prompt use the command:
lsblk
This will list the filesystems by device. One of them will be your boot partition, another will be the device that holds your broken VM’s root filesystem. In my case the 2 partitions of interest were /dev/nvme0n1p1 and /dev/nvme0n1p2, the latter of which is my root partition.
Mount these two partitions
mount /dev/nvme0n1p1 /mnt
mount /dev/nvme0n1p2 /mnt/boot/efi
You should see your famiiliar old files and directories under /etc and /home.
Mount the necessary system directories:
for i in proc dev sys; do mount --bind /$i /mnt/$i; done
Chroot into your not-booting VM:
chroot /mnt
Post-chroot Diagnostic Steps
Re-install the kernel…
apt update
apt install --reinstall linux-image-generic
Check the contents of the EFI folder:
ls /mnt/boot/efi
You should see something like this:
EFI/
└── ubuntu/
├── grubaa64.efi
└── grub.cfg
If the directory is empty, you need a GRUB fix…
Hopefully you don’t need to reinstall GRUB. This should be enough:
Anyway – here’s a few cheeky scripts for testing a handful (for now) of aspects of the CIS Benchmarks 2.0 for Azure. You have to populate the subscriptions.txt file for each.
Each subdirectory under the repository root corrresponds with a CIS Benchmark reference for Azure 2.0:
1.4, 1.5 – Review Guest Users – script list the Guest users configured in Entra
1.23 – Ensure That No Custom Subscription Administrator Roles Exist
3.1 – Ensure that ‘Secure transfer required’ is set to ‘Enabled’ [Storage Accounts]
3.2 – Ensure that ‘Enable Infrastructure Encryption’ for Each Storage Account in Azure Storage is Set to ‘enabled’
3.7 – Ensure that ‘Public access level’ is disabled for storage accounts with blob containers
3.10 – Ensure Private Endpoints are used to access Storage Accounts
3.11 – Ensure Soft Delete is Enabled for Azure Containers and Blob Storage
3.12 – Ensure Storage for Critical Data are Encrypted with Customer Managed Keys
3.15 – Ensure the “Minimum TLS version” for storage accounts is set to “Version 1.2”
5.1.3 – Ensure the Storage Container Storing the Activity Logs is not Publicly Accessible
5.1.6 – Ensure that Network Security Group Flow logs are captured and sent to Log Analytics
6.5 – Ensure that Network Security Group Flow Log retention period is ‘greater than 90 days’
6.7 – Ensure that Public IP addresses are Evaluated on a Periodic Basis (lists the addresses)
7.4 – Ensure that ‘Unattached disks’ are encrypted with ‘Customer Managed Key’ (CMK) (lists unattached disks)
8.2 – Ensure that the Expiration Date is set for all Keys in Non-RBAC Key Vaults (usually all key vaults will be RBAC enabled, making this control non-applicable. One script lists the RBAC and non-RBAC Key Vaults, then there’s an untested script for listing the non-expiring keys)
8.3 – Ensure that the Expiration Date is set for all Secrets in RBAC Key Vaults. The script is untested because of a lack of access to a test key vault(s).
8.4 – Ensure that the Expiration Date is set for all Secrets in Non-RBAC Key Vaults (usually all key vaults will be RBAC enabled, making this control non-applicable. One script lists the RBAC and non-RBAC Key Vaults, then there’s an untested script for listing the non-expiring secrets)
10.1 – Ensure that Resource Locks are set for Mission-Critical Azure Resources
Some of the cli scripts offered by CIS in their Azure benchmark don’t work – Azure changes faster than the benchmarks after all. The above were tried and tested in a real live environment (no, those are not the subscription IDs listed in the subscriptions.txt files!!). 5.1.6 is an example. The ‘nsg’ parameter was made obsolete. Technically the script will run with a warning if the ‘nsg’ parameter is used, but anyway I have done as suggested and used the ‘–location and –name combination’ in the az network watcher command instead.
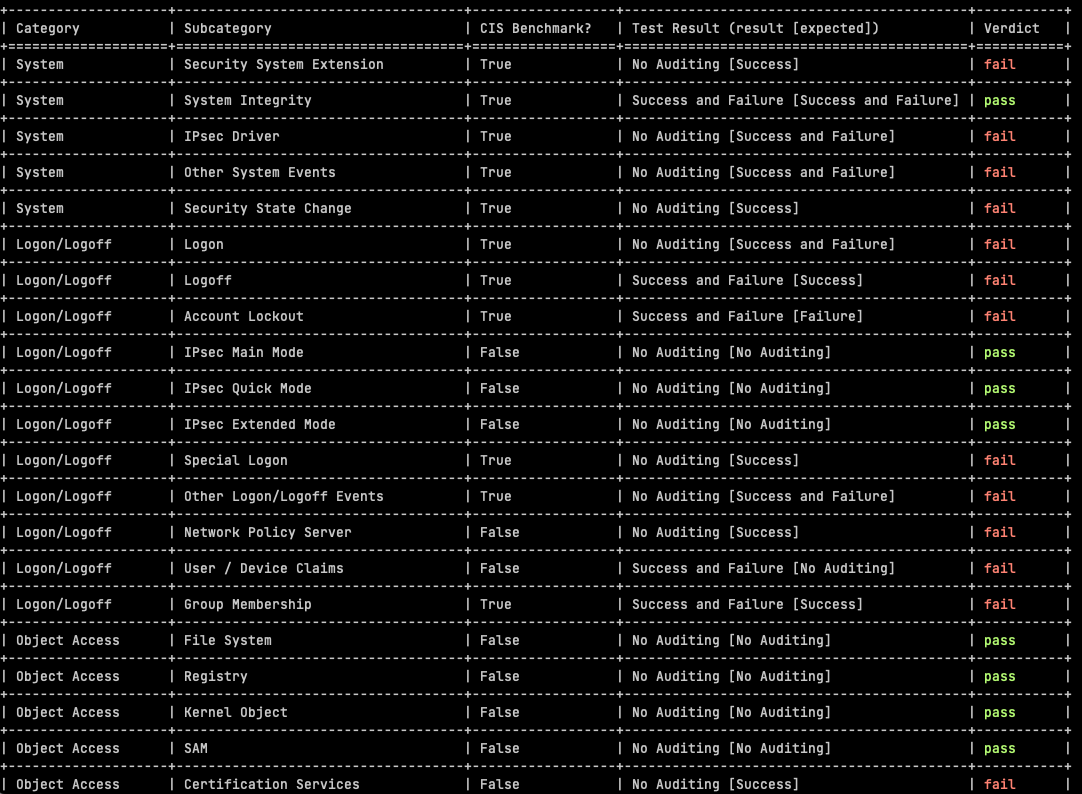
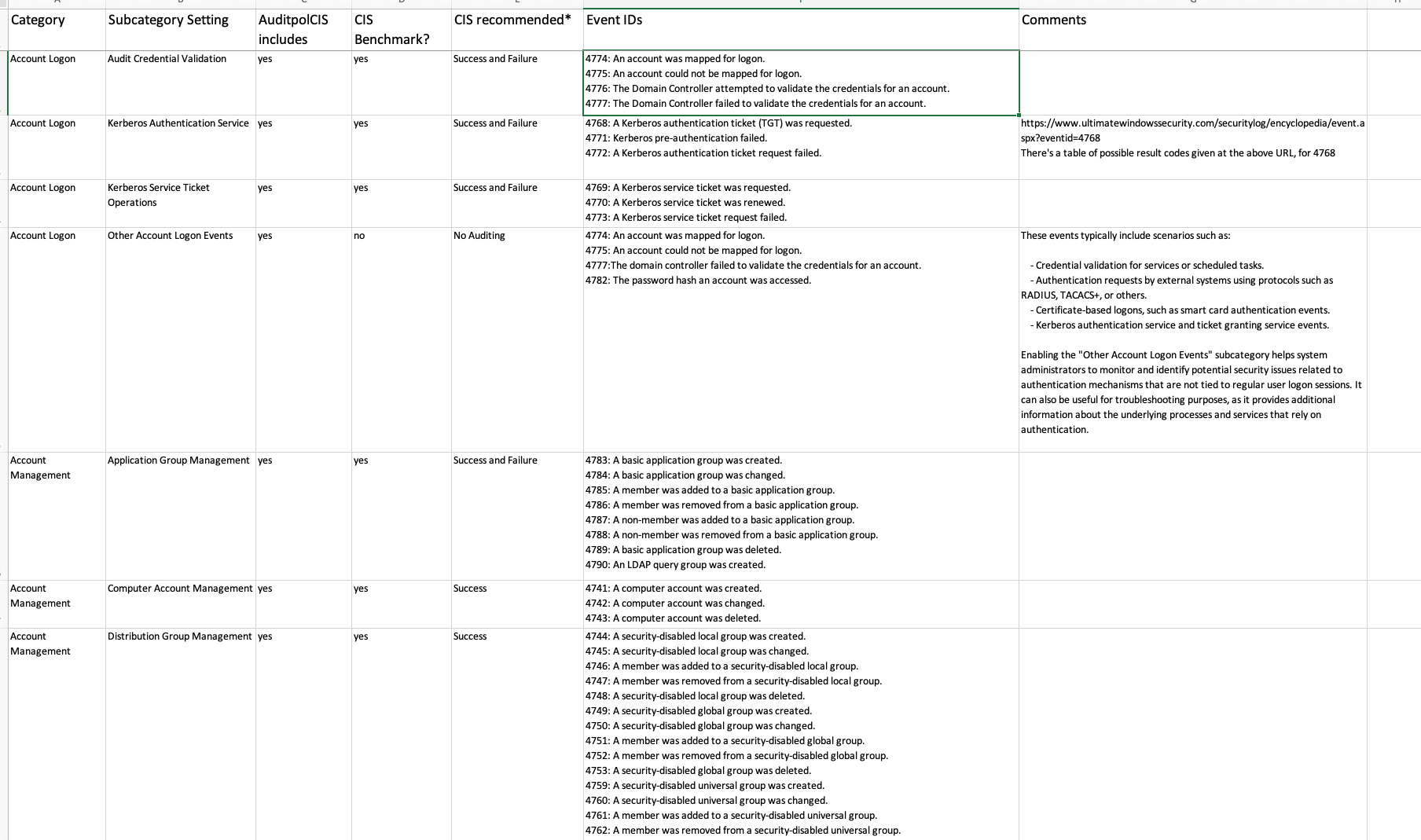
In the previous post on the subject of Windows SIEM, we covered the CIS benchmarks for Windows Auditing Policy in a spreadsheet, which was provided freely (really, actually free).
This week we introduce a python open source tool we have developed, to automate the CIS Benchmark testing.
The automated assessment results from AuditpolCIS, as it’s based on CIS Benchmarks, helps in the support of meeting audit requirements for a number of programs, not least PCI-DSS:
Audit account logon events: Helps in monitoring and logging all attempts to authenticate user credentials (PCI-DSS Requirement 10.2.4).
Audit object access: Monitors access to objects like files, folders, and registry keys that store cardholder data (PCI-DSS Requirement 10.2.1).
Audit privilege use: Logs any event where a user exercises a user right or privilege (PCI-DSS Requirement 10.2.2).
Local log files sizes and retention policies are useful in assessing compliance with e.g. 5.3.4 and 10.5.1 requirements (PCI-DSS 4). There should be a block of text after the audit policy results.
Usage / Setup
First you will to set up a Python Virtual Environment. Ensure that you have Python installed on your system (Python 3.10 was used in development). If not, download and install Python from the official website: https://www.python.org/downloads/
Open a Command Prompt or terminal window and navigate to the folder where you extracted the AuditpolCIS project.
Run the following command to create a new virtual environment:
python -m venv venv
Activate the virtual environment by running:
For Windows:
venv\Scripts\activate
For macOS/Linux:
source venv/bin/activate
Install the required Python packages from the requirements.txt file by running:
pip install -r requirements.txt
You will need a .env file in your project root. The contents relate to the target you wish to test:
HOSTNAME='<Windows box IP address or host name>' USERNAME='<Windows user account name>' PASSWORD='<account password>'
Make sure to assign the right ownership and permission on .env. Usually the permissions will be 600.
Once the virtualenv is enabled, you can run the code:
The CIS benchmarks are based on Windows 2019 Server but they apply to other target varients on a Windows theme. I know none of you will have EOL Windows versions. <Sarcasm engaged>I mean in 22 years of consulting, i’ve never seen any out-of-support warez in critical business usage</Sarcasm engaged>.
Powershell is not required on the target but use of Powershell is also not a crime. Yes, that was a security person who said that.
Sustainability / Use of Regex
I had to use some fairly snazzy regex to pull out Categories (category_pattern = r'^(\w+.*?)(\r)?$') and Subcategories (subcategory_pattern = r'^( {2})([^ ]+.*?)(?=\s{3,})(.*\S)') from the auditpol command output. I did look at more sustainable ways of achieving the same goal, although admittedly i didn’t spend much time doing that. One thing has been clear for a long time with Windows – don’t go looking for registry keys because that can be very painful. Not only is documentation for a key location somewhat thin and erroneous, the key loation also often changes across Windows versions. ChatGPT‘s lack of knowledge of Windows reg keys bears testimony to the previous comments.
So there are two sources of Subcategory names – there is cis-benchmarks.yaml and there is the output of the auditpol /get /category:* command. If there are entries in the YAML file which are not in the auditpol output, they are flagged in the script output, and the same is true vice versa. So if you make spelling mistakes in the excel sheet or YAML file, it will be flagged. It can also happen that auditpol output subcategories do not reflect the CIS Benchmarks subcategories, perhaps with different Windows versions as targets. Any of these categories will be flagged by the script and listed below the pass/fail results.
If you want to change the verdicts or [Sub]Category names, you are of course free to do so. You can edit the cis-benchmarks.yaml file, or edit the included spreadsheet, followed by running the included genyaml.py.
I know use of AutoAddPolicy with Paramiko in Python is not good form, but also assume that as an admin in the position of someone who performs daily tasks using administrative rights, that you know your hosts. Sometimes security people do get in the way of progress, when there’s low risk issues afoot. Use of RejectPolicy instead of auto-add would be one such case.
Tests Rationalisation
Some of the tests included are not a CIS Benchmark (out of 59 tests, 32 are CIS Benchmarks, whereas 27 are not). It’s not clear why the subcategories were omitted by CIS but anyway – in these cases we have made an assessment based on logging events volume for this subcategory, versus the security value of the subcategory. Most of these are just noise, and in many cases, very high volume noise, so we have advised “No Auditing”.
Customising Test Criteria
The testing template is formed of the YAML file cis-benchmarks.yaml. If you prefer to make changes to the testing template with Excel, the sheet is CIS-Audit-Reqs-Windows2019Server.xlsxin the code root. You can then use the python script genyaml.py to generate a new YAML file (you will need to use the right virtualenv, see above for usage instructions).
In our 2021 blog post, we focused on identifying quick wins for optimizing Windows Events, and provided a free spreadsheet (really free, not even a regwall) that indicated Windows Events that could be safely ignored, some of which cost lots for SIEM engines to ingest. This post takes a broader Windows Audit Policy view, and offers another free resource – this time taking a broader look in the context of comparing your setup for Windows Audit Policy, and the venerable CIS Benchmark for Windows 2019 Server.
If there’s sufficient interest i’ll follow up with a development effort for a Python tool (also freely available, on Github) that connects to your Windows server and performs the CIS Benchmark assessment as indicated in the spreadsheet.
SIEM Nightmares
Based on many first hand observations and second hand accounts, it’s not a stretch to say that many organisations are suffering from SIEM configuration issues, for which the result is a low signal-to-noise ratio. Your SIEM is ingesting lots of events, many of which are not at all helpful, and with most vendors charging by volume, it gets expensive. At the same time, the false negative problem is all too common. Forensics investigations reveal all too often that there are no events recorded by the expensive SIEM, that even closely relate to the incident. I hope you are never in this scenario. The short-term impact is never good.
Taking SIEM as a capability, if one is to advise on how to improve things, it is rarely ever about the technology. When one asks Analysts (and based on job postings, also hiring managers) about SIEM, it’s clear the first thing that comes to mind is Splunk. ELK, Sentinel, etc. I would estimate the technology-only focus with SIEM to be the norm rather than the exception, and it comes hand-in-hand with a failure to detect privilege elevations, and lateral movements for example.
There are some advisories that we can give out that are independent of your architecture, but many questions about SIEM configuration can only be answered by you, using your knowledge of the IT landscape in your organisation. The advisories in the referenced spreadsheet cover the “noise” part of the signal-to-noise ratio. These are events that are sure to be noise to at least a 90% level of assurance, from a security perspective.
Addtional Context on the Spreadsheet
Some context around the spreadsheet: where there is a CIS Benchmark metric for a specific Audit Subcategory, the spreadsheet follows exactly the CIS recommended setting. But there are some (e.g. DS Access –> Directory Service Access) where this subcategory was not covered by CIS. In these cases, an assessment is made based on our real-experience observations of logging volumes, versus the security (not the IT diagnostic, or other value) value of Audit Subcategories. In this case of the Directory Service Access subcategory, it can be turned off from a security perspective.
There is limited information available regarding actual experiences with specific event ID volumes. In 2018, I had the opportunity to track Windows events in a Splunk architecture for a government department. During this time, I recorded the occurrences of events over a 24-hour period on a network of approximately 150 Windows servers of various versions, some of which were quite exotic. This information has been valuable in supporting decisions related to whether or not to disable auditing.
SIEM Forwarder Filtering
There is another option offered by some SIEM vendors and that is to filter events by Event ID. Overall, the more resource-friendly approach is to prevent the events being generated at source, but in many cases this may not be feasible. Splunk for example allows you to filter at forwarders (via the inputs.conf file on the Splunk forwarder. This file is usually located in the $SPLUNK_HOME/etc/system/local/ directory … more info – BTW it looks like Splunk agrees with us on the 4662 event mentioned as an example above. Yay!).
Credits and Disclaimers
Windows Events are sometimes tricky to understand, both with respect of what the developers intended with those events, and the conditions under which they are generated. Sometimes with Windows Events, we are completely in unknown territory, even if there is some Microsoft documentation that covers them. Here’s one example from Microsoft documentation to fill us with confidence – “This auditing subcategory should not have any events in it, but for some reason Success auditing will enable the generation of event 4985″.
Ultimately only you can decide what’s best for the health of your SOC/SIEM. Only you know your network and your applications. The document supplied here was only intended as a guide, and to aid decision making. It was not intended to make decisions for you.
The cybersecurity landscape often focuses on the more sensational aspects, such as high-profile hacks or fake influencers, which can overshadow the essential work done by countless professionals in the background. These unsung heroes are dedicated to ensuring the stability and security of our digital infrastructure, and their contributions should not be underestimated. Among those are tthe likes of Randy Franklin Smith (founder of Ultmate Windows Security) who has put together an “encyclopedia” of Windows Event IDs. The experiences shared there were used in-part to form a view on whether or not to reject or accept certain Windows Events.
Before i continue, it’s pertinent to gives a heads up: nothing in this article relates to ChatGPT. Sorry.
Lots of fuss was abound this morning (on the back of articles from yesterday with attention-grabbing headlines) regarding these 2 vulnerabilties disclosed, reported as CVE-2023-20078 and CVE-2023-20079. The first of these is rated 9.8 under CVSS 3.1!! (Oh no).
A few points:
Affected products: Cisco IP Phone 6800, 7800, 7900, and 8800 Series.
The first vulnerability (CVE-2023-20078) is given as an RCE with instant-root, with the web-based management interface of the phone. The other is noted as a DoS condition.
Whereas the aforementioned sounds bad, do you have your phones facing the Internet with a public IPv4 address? Probably not. So the attacker would need an internal presence to exploit this condition. If they have an internal presence, are they really going to be going after your phones? They might one supposes. Only you can answer this question.
The CVSS rating of 9.8. About that. Lots of stuff is rated 10. Lots of stuff that shouldn’t be. It’s a long story but CVSS ratings have been slammed multiple times by multiple esteemed analysts over the past 5 years. This case here is interesting because we’re talking about phones… the 2nd vulnerability covered is given a 7.8 rating, primarily because its ONLY a DoS . But with YOUR organisation, maybe DoS on your phones is worse than a remote take-over of the phones. CVSS ratings are not based on YOUR network. The folks who put together these ratings know nothing about YOUR organisation. You have to figure out your own risks based on threat modelling (I prefer the OWASP metholodogy).
The potential for an automated attack is also there.
At the time of writing there was no publicity about attacks in the wild or public disclosed exploit code.
Cisco has released software updates that address these vulnerabilities.
The RCE as root might get some attention. Usually this is bad development or sys admin practice – to have processes running with super user privileges unnecessarily. However in this case the phone management software is management software and as such needs to manage – it needs root privileges. Let’s not bash Cisco over this one.
Finally – a blast from the past. What does Cisco have against web interfaces? A bug I remember that was useful in pen tests, primarily for learning about the target network, involved being able to pass commands under Level 15 (the highest) privileges with no authentication. The advice from Cisco was really something like ‘don’t use HTTP – disable it’.
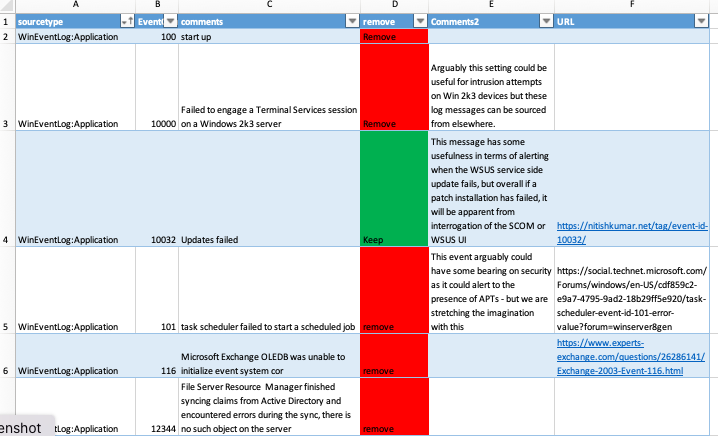
There has been a modicum of interest in a Windows spreadsheet I shared on social media recently, that if absorbed and acted upon, can be a early no-brainer win with SIEM products that are licensed based on volume or Events Per Second (EPS).
Its no big secret that Windows machines, virtual or real, are noisy. Clients I worked with – I would estimate 90%, for various reasonsdon’t act on the noise from Windows devices and it’s costing them a fortune (right or wrong, approx 50% of those prioritise other tasks).
In Splunk, one can use searches to estimate the benefit of removing noisy Windows events, and what I found was quite a broad range of results. It makes little sense to give the full breakdown because the result depends heavily on the spread and amount of Windows to other Operating Systems (OS). But there were a couple of cases where logging events volume was reduced by 70%.
Some points to note:
If the “remove” events are removed, Windows devices become very quiet. Some organisations use events as an indicator of “alive” rather than using active host monitoring. So with this logging configuration, an alternative (more sensible) host monitoring method is needed.
Removing these events is highly unlikely to ever result in a failure to detect an attack, but being 100% certain of this is impossible.
The most critical aspect of logging isn’t related to these events at all, its about your custom use cases. An example: a usual scenario is for a database listening service to accept application level connections on its listening service port (e.g. 1521 TCP is default for Oracle DB), and the source will be a web or middleware tier. So – configure an alert for when connections come from a source other than the middleware/application tier.
Very little actual analysis of Windows events and their purpose is known, or if it is known it is certainly not shared anywhere. There are some historical aspects to many of these events in that they’ve been around for more than 20 years but were never documented particualrly well, apart from here. I have added some insight but not for all events. Hence: if anyone would like any of the contents added or edited, feel free to comment below.
The context here is security. For other logging use cases, other events may need to be switched on.
The major versions of MS Windows Server that this journal applies to are: 2003, 2008, 2012. Many will apply to both 2016 and 2019.
So here are the links.. note there is no reg or pay wall. You will not be tracked and no data will be held about you. This is a completely free resource for you to collect anonymously:
In latish 2020, I moved Netdelta from a Docker deployment to Kubernetes, partly to see what all this Kubernetes jazz is about, and partly to investigate whether it would help me with the management of Netdelta containers for different punters, each of whom has their own docker container and Apache listening service.
I studiously went through the Kubernetes quick tutorial and found i had to investigate the documentation some more. Even then some aspects weren’t covered so well. This post explains what i did to deploy an app into Kubernetes, and some of the gotchas i encountered along the way, that were not covered so well in the Kubernetes documentation, and I summarise with a view of Kubernetes and give my view on: is the hype justified? Will I continue to host Netdelta in Kubernetes?
This is not a Kubernetes tutorial – it does assume some prior exposure on behalf of the reader, but nonethless links to the relevant documentation when some Kubernetes concepts are covered.
This post isn’t about Netdelta, but for illustrative purposes: Netdelta aids with the detection of unauthorised changes, and hacker shells, by running one-off port scans, or scheduled jobs, comparing the results with the previous scan, and alerting on changes. This is more chunky than it sounds, mostly because of the analytics that goes into false positives detection. In the Kubernetes implementation, scan results are held in a stateful persistent volume with MySQL.
Netdelta’s docker config can be dug into here, but to summarise the docker setup:
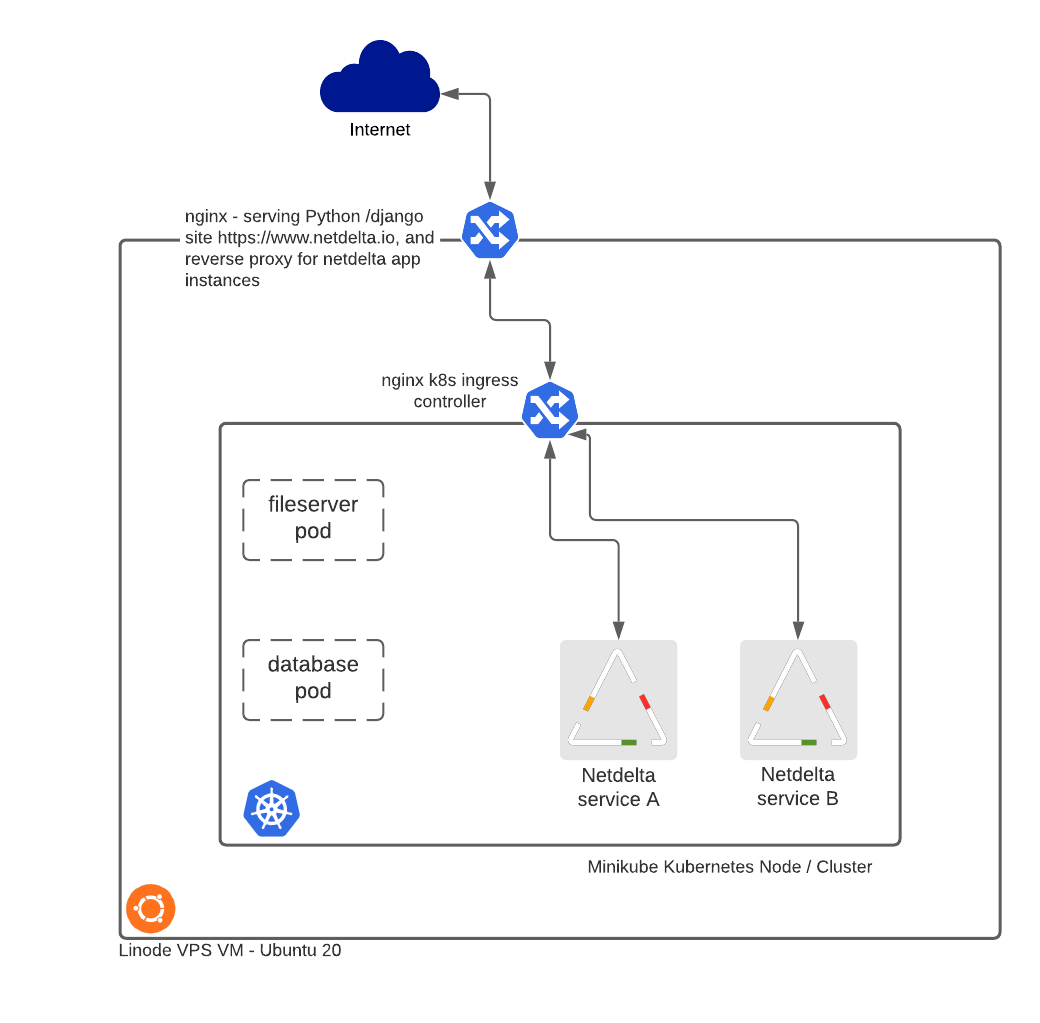
The data flows aspect reflects what is not exactly a bare metal deployment. A Linode-hosted VM running Ubuntu 20 is the host, then the Kubernetes node is minikube, with another node running on a Raspberry pi 3 – the latter aspect not being a production facility. The pi 3 was only to test how well the config would work with load balancing, and Kubernetes Replicasets across nodes.
Reverse Proxy
Ingress connections from the internet are handled first by nginx acting as a reverse proxy. Base URLs for Netdelta are of the form https://www.netdelta.io/<site>. The nginx config …
This is passing a URL with a first level of <site> to be processed at local.netdelta.io, which is locally resolvable, and is localhost. This is where the nginx Kubernetes Ingress Controller comes into play. The pods in kubernetes have NodePorts configured but these aren’t necessary. The nginx ingress controller takes connections on port 80, and routes based on service names and the defined listening port:
So the nginx ingress controllers sees the connection forwarded from local.netdelta.io with a URL request of local.netdelta.io/<site>. The requests matches a rule, and forwards to the Kubernetes Service of the same name. The entity that actually answers the call is a docker container masquerading as a Kubernetes Pod, which is part of a deployment. The next step in the data flow is to route the connection to the specified Kubernetes Service which is covered briefly here but in more detail later in the coverage of DNS.
The “service” aspect has the effect of exposing the pod according to the service setup:
┌──(iantibble㉿bionic)-[~/netdd/k8s]
└─$ kubectl get services -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 443/TCP 119d
mysql-netdelta ClusterIP 10.97.140.111 3306/TCP 39d app=mysql-netdelta
netdelta-barbican NodePort 10.103.160.223 9004:30460/TCP 36d app=netdelta-barbican
netdelta-xynexis NodePort 10.102.53.156 9005:31259/TCP 36d app
DNS
There’s an awful lot of waffle out there about DNS and Kubernetes. Basically – and I know the god of devops won’t let me in heaven for saying this, but making a service in Kubernetes leads to DNS being enabled. DNS in a multi-namespace, multi-node scenario becomes more intreresting of course, and there’s plenty you can configure that’s outside the scope of this article.
Netdelta’s Django settings.py defines a host and database name, and has to be able to find the host:
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', # Add 'postgresql_psycopg2', 'mysql', 'sqlite3' or 'oracle'. 'NAME': 'netdelta-SITENAME', # Not used with sqlite3. 'USER': 'root', # Not used with sqlite3. 'HOST': mysql-netdelta, 'PASSWORD': 'NOYFB', 'OPTIONS': dict(init_command="SET sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER'"), } }
This aspect was poorly documented and was far from obvious: the spec.selector field of the service should match the spec.template.metadata.labels of the pod created by the Deployment.
The Application Hosting in Kubernetes
Referring back to the diagram above, there are pods for each Netdelta site. How was the Docker-hosted version of Netdelta represented in Kubernetes?
Has the effect of creating a pod and a container for the Django application, celery and Apache stack:
┌──(iantibble㉿bionic)-[~]
└─$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
fileserver 1/1 1 1 25d
mysql-netdelta 1/1 1 1 25d
netdelta-barbican 1/1 1 1 25d
┌──(iantibble㉿bionic)-[~]
└─$ kubectl get pods
NAME READY STATUS RESTARTS AGE
fileserver-6d6bc54f6c-hq8lk 1/1 Running 2 25d
mysql-netdelta-5fd7757c66-xqp2j 1/1 Running 2 25d
netdelta-barbican-68d78c58bd-vnqdn 1/1 Running 2 25d
K8s Equivakent of Docker Entrypoint Script Parameters
Some other points perhaps worthy of mention were around the Docker v Kubernetes aspects. My docker run command for the netdelta application container was like this:
So there’s 4 parameters for the entryscript: site, port, le, and cert. The last two are about letsencrypt certs which won’t be covered here. These are represented in the Kubernetes Deployment YAML in spec.template.spec.containers.args.
Private Image Repository
spec.template.spec.containers.image is set to registry.netdelta.io/netdelta/<site>:<version tag>. Yes, that’s right folks, i’m using a private registry, which is a lot of fun until you realise how hard it is to manage the images there. The setup and management of the private registry won’t be covered here but i found this to be useful.
One other point is about security and encryption in transit for the image pushes and pulls. I’ve been in security for 20 years and have lots of unrestricted penetration testing experience. It shouldn’t be necessary or mandatory to use HTTPS over HTTP in most cases. Admittedly i didn’t spend long trying, but i could not find a way to just use good old clear-text port 80 over 443, which in turn meant i had to configure a SSL certifcate with all the management around it, where the risks are far from justifying such a measure.
PV Mounts
In Dockerland I was using Docker Volumes for persistent storage of logs and application data. I was also using it for the application codebase, and any updates would be sync’d with containers by docker exec wrapped in a BASH script.
There was nothing unexpected in the deployment of the PVCs/PVs, but a couple of points are worth mentioning:
PV Filesystem mounts: Netdelta container deployment involves a custom image from COPY (Docker command) of files from a local source to the image. Then the container is run and the application can find the required files. The problem i ran into was about having filesystems mounted over the directories where my application container expected to find files. This meant i had to change my container entryscript to sync with the image when the Pod is deployed, whereas previously the directories were built-out from the docker image build.
/tmp as default PV files location: if you SSH to the node (minikube container in my case), you will find the mounted filesystems under /tmp. /tmp is a critical directory for the good health of any Linux-based system and it needs to be 777 (i.e. read and writeable by unauthenticated users and processes) with a sticky bit. This is one that for whatever reason doesn’t find its way into security checklists for Kubernetes but it really does warrant some attention. This can be changed by customising Kubernetes Storage Classes. There’s one pointer here.
Database and Fileserver
The MySQL Database service was deployed as a custom built container with my Docker setup. There was no special reason for this other than to change filesystem permissions, and the fact that the listening service needed to be “exposed” and the database config changed to bind to 0.0.0.0 instead of localhost. What i found with the Kubernetes Pod was that I didn’t need to change the Mysql config at all and spec.ports.targetport had the effect of “exposing” the listening service for the database.
The main reason for using a fileserver in the Dcoker deployment of Netdelta was to act as a container buffer between Docker Volumes and application containers. My my Unix hat on, one is left wondering how filesystem persmissions will work (or otherwise) with file read and writes across network mounted disparate unix systems, where even if the same account names exist on each system, perhaps they have different UIDs (BSD-derived systems use the UID to define ownership, not the name on the account). Moreover it was advised as a best practice measure in the Docker documentation to use an intermediate fileserver. Accordingly this was the way i decided to go with Kubernetes, with a “sidecar” Pod as a fileserver, which mounts the PVs onto the required mount points.
To K8s Or Not To K8s?
When you think about the way that e.g. Minikube is deployed – its a docker container. If you run a docker ps -a, you can see all the mechanics at work. And then if you SSH to the minikube, you can do another docker ps -a, and you see everything to do with Kubernetes pods and containers in the output. This seems like a mess, and if it isn’t, it will do until the mess actually arrives.
Furthermore, you don’t even want to look at the routing tables or network interfaces on the node host. You just cannot unsee that.
There is some considerable complexity here. Further, when you read the documentation for Kubernetes, it does have all the air of documentation written by programmers. We hear a lot about the lack of IT-skilled people, but what is even more lacking, are strategic thinkers (e.g. * [wildcard] Architects) who translate top level business design requirements into programming tactical requirements.
Knowing how Kubernetes works should be enough to know whether it’s really going to be beneficial or not to host your containers there. If you’re not sure you need it, then you probably don’t. In the case of Netdelta, if i have lots and lots of Netdelta sites to manage then i can go with Kubernetes, and now that i have seen Netdelta happily running in Kubernetes with both scheduled celery jobs and manual user-initiated scans, the transition will be a smooth one. In the meantime, I can work with Docker containers alone, with the supporting BASH scripts, whuch are here if you’re interested.
Part Two – Threat and Vulnerability Management – Application Security
Part Three – Threat and Vulnerability Management – Other Layers
Part Four – Logging
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Threat and Vulnerability Management (TVM) – Other Layers
This article covers the key principles of vulnerability management for cloud, devops, and devsecops, and herein addresses the challenges faced by fintechs.
Fintechs are focussing on application security, which is good, but not so much in the security of other areas such as containers, IaaS/SaaS VMs, and little thought is ever given to the supply of patches and container images (they need to come from an integral source – preferably not involving pulling from the public Internet, and the patches and images need to be checked for integrity themselves).
And in general with vulnerability assessment (VA), we in infosec are still battling a popular misconception, which after a quarter of a decade is still a popular misconception – and that is the value, or lack of, of unauthenticated scanners such as OpenVAS and Nessus. More on this later.
The Overall Approach
The design process for a TVM capability was covered in Part One. Capabilities are people, process, and technology. They’re not just technology. So the design of TVM is not as follows: stick an OpenVAS VM in a VPC, fill it with target addresses, send the auto-generated report to ops. That is actually how many fintechs see the TVM challenge, or they just see it as being a purely application security show.
So there is a vulnerability reported. Is it a false positive? If not, then what is the risk? And how should the risk be treated? In order to get a view of risk, security professionals with an attack mindset need to know
the network layout and data flows – think from the point of view of an attacker – so for example if a front end web micro-service is compromised, what can the attacker can do from there? Can they install recon tools such as a port scanner or sniffer locally and figure out where the back end database is? This is really about “trust relationships”. That widget that routes connections may in itself seem like a device that isn’t worthy of attention, but it routes connections to a database hosting crown jewels…you can see its an important device and its configuration needs some intense scrutiny.
the location and sensitivity of critical information assets.
The ease and result of an exploit – how easy is it to gain a local shell presence and then what is the impact?
The points above should ideally be covered as part of threat modelling, that is carried out before any TVM capability design is drafted.
if the engineer or analyst or architect has the experience in CTF or simulated attack, they are in a good position to speak confidently about risk.
There are two types: unauthenticated and credentialed or authenticated scanners.
Many years ago i was an analyst running VA scans as part of an APAC regional accreditation service. I was using Nessus mostly but some other tools also. To help me filter false positives, I set up a local test box with services like Apache, Sendmail, etc, pointed Nessus at the box, then used Ethereal (now Wireshark) to figure out what the scanner was actually doing.
What became abundantly obvious with most services, is that the scanner wasn’t actually doing anything. It grabs a service banner and then …nothing.
I thought initially there was a problem with my setup but soon eliminated that doubt. There are a few cases where the scanner probes for more information but those automated efforts are somewhat ineffectual and in many cases the test that is run, and then the processing of the result, show a lack of understanding of the vulnerability. A false negative is likely to result, or at best a false positive. The scanner sees a text banner response such as “apache 2.2.14”, looks in its database for public disclosed vulnerability for that version, then barfs it all out as CRITICAL, red colour, etc.
Trying to assess vulnerability of an IaaS VM with unauthenticated VA scanners is like trying to diagnose a problem with your car without ever lifting the hood/bonnet.
So this leads us to credentialed scanners. Unfortunately the main players in the VA space pander to unauthenticated scans. I am not going to name vendors here, but its clear the market is poorly served in the area of credentialed scanning.
It’s really very likely that sooner rather than later, accreditation schemes will mandate credentialed scanning. It is slowly but surely becoming a widespread realisation that unauthenticated scanners are limited to the above-mentioned testing methodology.
So overall, you will have a set of Technical Security Standards for different technologies such as Linux, Cisco IoS, Docker, and some others. There are a variety of tools out there that will get part of the job done with the more popular operating systems and databases. But in order to check compliance to your Technical Security Standards, expect to have to bridge the gap with your own scripting. With SSH this is infinitely feasible. With Windows, it is harder, but check Ansible and how it connects to Windows with Python.
Asset Management
Before you can assess for vulnerability, you need to know what your targets are. Thankfully Cloud comes with fewer technical barriers here. Of course the same political barriers exist as in the on-premise case, but the on-premise case presents many technical barriers in larger organisations.
Google Cloud has a built-in feature, and with AWS, each AWS Service (eg Amazon EC2, Amazon S3) have their own set of API calls and each Region is independent. AWS Config is highly useful here.
SaaS
I covered this issue in more detail in a previous post.
Remember the old times of on-premise? Admins were quite busy managing patches and other aspects of operating systems. There are not too many cases where a server is never accessed by an admin for more than a few weeks. There were incompatibilities and patch installs often came with some banana skins around dependencies.
The idea with SaaS is you hand over your operating systems to the CSP and hope for the best. So no access to SMB, RDP, or SSH. You have no visibility of patches that were installed, or not (!), and you have no idea which OS services are enabled or not. If you ask your friendly CSP for more information here, you will not get a reply, and if you do they will remind you that handed over your 50-million-lines-of-source-code OSes to them.
Here’s an example – one variant of the Conficker virus used the Windows ‘at’ scheduling service to keep itself prevalent. Now cloud providers don’t know if their customers need this or not. So – they verge on the side of danger and assume that they do. They will leave it enabled to start at VM boot up.
Note that also – SaaS instances will be invisible to credentialed VA scanners. The tool won’t be able to connect to SSH/RDP.
I am not suggesting for a moment that SaaS is bad. The cost benefits are clear. But when you moved to cloud, you saved on managing physical data centers. Perhaps consider that also saving on management of operating systems maybe taking it too far.
The patches need to come from an integral source – this is where DNSSEC can play a part but be aware of its limitations – e.g. update.microsoft.com does not present a ‘dnskey’ Resource Record. Vendors sometimes provide a checksum or PGP cryptogram.
Some vendors do not present any patch integrity checksums at all and will force users to download a tarball. This is far from ideal and a workaround will be critical in most cases.
Redhat has their Satellite Network which will meet most organisations’ requirements.
For cloud, the best approach will usually be to ingress patches to a management VPC/Vnet, and all instances (usually even across differing code maturity level VPCs), can pull from there.
Delta Testing
Doing something like scanning critical networks for changes in advertised listening services is definitely a good idea, if not for detecting hacker shells, then for picking up on unauthorised changes. There is no feasible means to do this manually with nmap, or any other port scanner – the problem is time-outs will be flagged as a delta. Commercial offerings are cheap and allow tracking over long histories, there’s no false positives, and allow you to create your own groups of addresses.
Penetration Testing
There’s ideal state, which for most orgs is going to be something like mature vulnerability management processes (this is vulnerability assessment –> deduce risk with vulnerability –> treat risk –> repeat), and the red team pen test looks for anything you may have missed. Ideally, internal sec teams need to know pretty much everything about their network – every nook and cranny, every switch and firewall config, and then the pen test perhaps tells them things they didn’t already know.
Without these VM processes, you can still pen test but the test will be something like this: you find 40 holes of the 1000 in the sieve. But it’s worse than that, because those 40 holes will be back in 2 years.
There can be other circumstances where the pen test by independent 3rd party makes sense:
Compliance requirement.
Its better than nothing at all. i.e. you’re not even doing VA scans, let alone credentialed scans.
Wrap-up
It’s far from all about application security. This area was covered in part two.
Design a TVM capability (people, process, technology), don’t just acquire a technology (Qualys, Rapid 7, Tenable SC. etc), fill it with targets, and that’s it.
Use your VA data to formulate risk, then decide how to treat the risk. Repeat. Note that CVSS ratings are not particularly useful here. You need to ascertain risk for your environment, not some theoretical environment.
Credentialed scanning is the only solution worth considering, and indeed it’s highly likely that compliance schemes will soon start to mandate credentialed scanning.
Use a network delta tester to pick up on hacker shells and unauthorised changes in network services and firewalls.
Being dynamic with Kubernetes and microservices has not yet killed your platform risk or the OS in general.
SaaS may be a step too far for many, in terms of how much you can outsource.
When you SaaS’ify a service, you hand over the OS to a CSP, and also remove it from the scope of your TVM VA credentialed scanning.
Penetration testing has a well-defined place in security, which isn’t supposed to be one where it is used to inform security teams about their network! Think compliance, and what ideal state looks like here.
Based on personal experience, and second hand reports, there’s still some confusion out there that results in lots of wasted time for job seekers, hiring organisations, and recruitment agents.
There is a want or a need to blame recruiters for any hiring difficulties, but we need to stop that. There are some who try to do the right thing but are limited by a lack of any sector experience. Others have been inspired by Wolf Of Wall Street while trying to sound like Simon Cowell.
It’s on the hiring organisation? Well, it is, but let’s take responsibility for the problem as a sector for a change. Infosec likes to shift responsibility and not take ownership of the problem. We blame CEOs, users, vendors, recruiters, dogs, cats, “Russia“, “China” – anyone but ourselves. Could it be we failed as a sector to raise awareness, both internally and externally?
So What Are Common Understandings Of Security Roles?
After 25 years+ we still don’t have universally accepted role descriptions, but at least we can say that some patterns are emerging. Security roles involve looking at risk holistically, and sometimes advising on how to deal with risk:
Security Engineers assess risk and design and sometimes also implement controls. BTW some sectors, legal in particular, still struggle with this. Someone who installs security products is in an IT ops role. Someone who upgrades and maintains a firewall is an IT ops role. The fact that a firewall is a security control doesn’t make this a security engineering function.
Security Architects take risk and compliance goals into account when they formulate requirements for engineers.
Security Analysts are usually level 2 SOC analysts, who make risk assessments in response to an alert or vulnerability, and act accordingly.
This subject evokes as much emotion as CISSP. There are lots of opinions out there. We owe to ourselves to be objective. There are plenty of sources of information on these role definitions.
No Aspect Of Risk Assessment != Security. This is Devops.
If there is no aspect of risk involved with a role, you shouldn’t looking for a security professional. You are looking for DEVOPS peeps. Not security peeps.
If you want a resource to install and configure tools in cloud – that is DEVOPS. It is not Devsecops. It is not Security Engineering or Architecture. It is not Landscape Architecture or Accounting. It is not Professional Dog Walker. it is DEVOPS. And you should hire a DEVOPS person. If you want a resource to install and configure appsec tools for CI/CD – that is DEVOPS. If you want a resource to advise on or address findings from appsec tools, that is a Security Analyst in the first case, DEVSECOPS in the 2nd case. In the 2nd case you can hire a security bod with coding experience – they do exist.
Ok Then So What Does A DevSecOps Beast Look Like?
DevSecOps peeps have an attack mindset from their time served in appsec/pen testing, and are able to take on board the holistic view of risk across multiple technologies. They are also coders, and can easily adapt to and learn multiple different devops tools. This is not a role for newly graduated peeps.
Doing Security With Non-Security Professionals Is At Best Highly Expensive
Another important point: what usually happens because of the skills gap in infosec:
Cloud: devops fills the gap.
On-premise: Network Engineers fill the gap.
Why doesn’t this work? I’ve met lots of folk who wear the aforementioned badges. Lots of them understand what security controls are for. Lots of them understand what XSS is. But what none of them understand is risk. That only comes from having an attack mindset. The result will be overspend usually – every security control ever conceived by humans will be deployed, while also having an infrastructure that’s full of holes (e.g. default install IDS and WAF is generally fairly useless and comes with a high price tag).
Vulnerability assessment is heavily impacted by not engaging security peeps. Devops peeps can deploy code testing tools and interpret the output. But a lack of a holistic view or an attack mindset, will result in either no response to the vulnerability, or an excessive response. Basically, the Threat And Vulnerability Management capability is broken under these circumstances – a sadly very common scenario.
SIEM/Logging is heavily impacted – what will happen is either nothing (default logging – “we have Stackdriver, we’re ok”), or a SIEM tool will be provisioned which becomes a black hole for events and also budgets. All possible events are configured from every log source. Not so great. No custom use cases will be developed. The capability will cost zillions while also not alerting when something bad is going down.
Identity Management – is not deploying a ForgeRock (please know what you’re getting into with this – its a fork of Sun Microsystems/Oracle’s identity management show) or an Azure AD and that’s it, job done. If you just deploy this with no thought of the problem you’re trying to solve in identity management, you will be fired.
One of the classic risk problems that emerges when no security input is taken: “there is no personally identifiable information in development Virtual Private Clouds, so there is no need for security controls”. Well – intelligence vulnerability such as database schema – attackers love this. And don’t you want your code to be safe and available?
You see a pattern here. It’s all or nothing. Either of which ends up being very expensive or worse. But actually come to think of it, expensive is the goal in some cases. Hold that thought maybe.
A Final Word
So – if the word risk doesn’t appear anywhere in the job description, it is nothing to do with security. You are looking for devops peeps in this case. And – security is an important consideration for cloud migrations.
Recently the venerable Brian Krebs covered a mass-DNS hijacking attack wherein suspected Iranian attackers intercepted highly sensitive traffic from public and private organisations. Over the course of the last decade, DNS issues such as cache poisoning and response/request hijacking have caused financial headaches for many organisations.
Wired does occasionally dip into the world of infosec when there’s something major to cover, as they did here, and Arstechnica published an article in January this year that quotes warnings about DNS issues from Federal authorities and private researchers. Interestingly DNSSEC isn’t covered in either of these.
The eggheads behind the Domain Name System Security Extensions (obvious really – you could have worked that out from the use of ‘DNSSEC’) are keeping out of the limelight, and its unknown as to exactly how DNSSEC was conceived, although if you like RFCs (and who doesn’t?) there is a strong clue from RFC 3833 – 2004 was a fine year for RFCs.
The idea that responses from DNS servers may be untrustworthy goes way back, indeed the Council of Elrond behind RFC 3833 called out the year 1993 as being the one where the discussion on this matter was introduced, but the idea was quashed – the threats were not clearly seen in the early 90s. An even more exploitable issue was around lack of access control with networks, but the concept of private networks with firewalls at choke points was far from widespread.
DNSSEC Summarised
For a well-balanced look at DNSSEC, check Cloudfare’s version. Here’s the headline paragraph which serves as a decent summary “DNSSEC creates a secure domain name system by adding cryptographic signatures to existing DNS records. These digital signatures are stored in DNS name servers alongside common record types like A, AAAA, MX, CNAME, etc. By checking its associated signature, you can verify that a requested DNS record comes from its authoritative name server and wasn’t altered en-route, opposed to a fake record injected in a man-in-the-middle attack.”
DNSSEC Gripes
There is no such thing as a “quick look” at a technical coverage of DNSSEC. There is no “birds eye view” aside from “it’s used for DNS authentication”. It is complex – so much so that’s it’s amazing that it even works at all. It is PKI-like in its complexity but PKIs do not generally live almost entirely on the Public Internet – the place where nothing bad ever happened and everything is always available.
The resources required to make DNSSEC work, with key rotation, are not negligible. A common scenario – architecture designs call out a requirement for authentication of DNS responses in the HLD, then the LLD speaks of DNSSEC. But you have to ask yourself – how do client-side resolvers know what good looks like? If you’re comparing digital signatures, doesn’t that mean that the client needs to know what a good signature is? There’s some considerable work needed to get, for example, a Windows 10/Server 2k12 environment DNSSEC-ready: client side configuration.
DNSSEC is far from ubiquitous. Indeed – here’s a glaring example of that:
So, maybe i’m missing something, but i’m not seeing any Resource Records for DNSSEC here. And that’s bad, especially when threat modelling tells us that in some architectures, controls can be used to mitigate risk with most attack vectors, but if WSUS isn’t able to make a call on whether or not its pulling patches from an authentic source, this opens the door for attackers to introduce bad stuff into the network. DNSSEC isn’t going to help in this case.
Don’t forget key rotation – DNSSEC is subject to key management. The main problem with Cryptography in the business world has been less about brute-forcing keys and exploiting algorithm weaknesses than is has been about key management weaknesses – keys need to be stored, rotated, and transported securely. Here’s an example of an epic fail in this area, in this case with the NSA’s IAD site. The page linked to by that tweet has gone missing.
For an organisation wishing to authenticate DNS responses, DNSSEC really does have to be ubiquitous – and that can be a challenge with mobile/remote workers. In the article linked above from Brian Krebs, the point was made that the two organisations involved are both vocal proponents and adopters of DNSSEC, but quoting from Brian’s article: “On Jan. 2, 2019 — the same day the DNSpionage hackers went after Netnod’s internal email system — they also targeted PCH directly, obtaining SSL certificates from Comodo for two PCH domains that handle internal email for the company. Woodcock said PCH’s reliance on DNSSEC almost completely blocked that attack, but that it managed to snare email credentials for two employees who were traveling at the time. Those employees’ mobile devices were downloading company email via hotel wireless networks that — as a prerequisite for using the wireless service — forced their devices to use the hotel’s DNS servers, not PCH’s DNNSEC-enabled systems.”
Conclusion
Organisations do need to take DNS security more seriously – based on what i’ve seen most are not even logging DNS queries and answers, occasionally even OS and app layer logs are AWOL on the servers that handle these requests (these are typically serving AD to the organisation in a MS Windows world!).
But we do need DNS. The alternative is manually configuring IP addresses in a load balanced and forward-proxied world where the Origin IP address of web services isn’t at all clear. We are really back in pen and paper territory if there’s no DNS. And there’s also no real, planet earth alternative to DNSSEC.
DNSSEC does actually work as it was intended and its a technically sound concept, and as in Brian’s article, it has thwarted or delayed attacks. It comes with the management costs of any key management system, and relies on private and public organisations to DNSSEC-ize themselves (as well as manage their keys).
While I regard myself an advocate of DNSSEC deployment, it’s clear there are legitimate criticisms of DNSSEC. But we need some way of authentication of answers we receive from public DNS servers. DNSSEC is a key management system that works in principle.
If the private sector applies enough pressure, we won’t be seeing so many articles about either DNS attacks or DNSSEC, because it will be one of those aspects of engineering that has been addressed and seen as a mandatory aspect of security architecture.