In our 2021 blog post, we focused on identifying quick wins for optimizing Windows Events, and provided a free spreadsheet (really free, not even a regwall) that indicated Windows Events that could be safely ignored, some of which cost lots for SIEM engines to ingest. This post takes a broader Windows Audit Policy view, and offers another free resource – this time taking a broader look in the context of comparing your setup for Windows Audit Policy, and the venerable CIS Benchmark for Windows 2019 Server.
If there’s sufficient interest i’ll follow up with a development effort for a Python tool (also freely available, on Github) that connects to your Windows server and performs the CIS Benchmark assessment as indicated in the spreadsheet.
SIEM Nightmares
Based on many first hand observations and second hand accounts, it’s not a stretch to say that many organisations are suffering from SIEM configuration issues, for which the result is a low signal-to-noise ratio. Your SIEM is ingesting lots of events, many of which are not at all helpful, and with most vendors charging by volume, it gets expensive. At the same time, the false negative problem is all too common. Forensics investigations reveal all too often that there are no events recorded by the expensive SIEM, that even closely relate to the incident. I hope you are never in this scenario. The short-term impact is never good.
Taking SIEM as a capability, if one is to advise on how to improve things, it is rarely ever about the technology. When one asks Analysts (and based on job postings, also hiring managers) about SIEM, it’s clear the first thing that comes to mind is Splunk. ELK, Sentinel, etc. I would estimate the technology-only focus with SIEM to be the norm rather than the exception, and it comes hand-in-hand with a failure to detect privilege elevations, and lateral movements for example.
There are some advisories that we can give out that are independent of your architecture, but many questions about SIEM configuration can only be answered by you, using your knowledge of the IT landscape in your organisation. The advisories in the referenced spreadsheet cover the “noise” part of the signal-to-noise ratio. These are events that are sure to be noise to at least a 90% level of assurance, from a security perspective.
Addtional Context on the Spreadsheet
Some context around the spreadsheet: where there is a CIS Benchmark metric for a specific Audit Subcategory, the spreadsheet follows exactly the CIS recommended setting. But there are some (e.g. DS Access –> Directory Service Access) where this subcategory was not covered by CIS. In these cases, an assessment is made based on our real-experience observations of logging volumes, versus the security (not the IT diagnostic, or other value) value of Audit Subcategories. In this case of the Directory Service Access subcategory, it can be turned off from a security perspective.
There is limited information available regarding actual experiences with specific event ID volumes. In 2018, I had the opportunity to track Windows events in a Splunk architecture for a government department. During this time, I recorded the occurrences of events over a 24-hour period on a network of approximately 150 Windows servers of various versions, some of which were quite exotic. This information has been valuable in supporting decisions related to whether or not to disable auditing.
SIEM Forwarder Filtering
There is another option offered by some SIEM vendors and that is to filter events by Event ID. Overall, the more resource-friendly approach is to prevent the events being generated at source, but in many cases this may not be feasible. Splunk for example allows you to filter at forwarders (via the inputs.conf file on the Splunk forwarder. This file is usually located in the $SPLUNK_HOME/etc/system/local/ directory … more info – BTW it looks like Splunk agrees with us on the 4662 event mentioned as an example above. Yay!).
Credits and Disclaimers
Windows Events are sometimes tricky to understand, both with respect of what the developers intended with those events, and the conditions under which they are generated. Sometimes with Windows Events, we are completely in unknown territory, even if there is some Microsoft documentation that covers them. Here’s one example from Microsoft documentation to fill us with confidence – “This auditing subcategory should not have any events in it, but for some reason Success auditing will enable the generation of event 4985″.
Ultimately only you can decide what’s best for the health of your SOC/SIEM. Only you know your network and your applications. The document supplied here was only intended as a guide, and to aid decision making. It was not intended to make decisions for you.
The cybersecurity landscape often focuses on the more sensational aspects, such as high-profile hacks or fake influencers, which can overshadow the essential work done by countless professionals in the background. These unsung heroes are dedicated to ensuring the stability and security of our digital infrastructure, and their contributions should not be underestimated. Among those are tthe likes of Randy Franklin Smith (founder of Ultmate Windows Security) who has put together an “encyclopedia” of Windows Event IDs. The experiences shared there were used in-part to form a view on whether or not to reject or accept certain Windows Events.
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Logging
Notice “Logging” is used here, not “SIEM”. With use of “SIEM”, there is often a mental leap, or stumble, towards a commercial solution. But there doesn’t necessarily need to be a commercial solution. This post invites the reader to take a step back from the precipice of engaging with vendors, and check first if that journey is one you want to make.
Unfortunately, in 2020, it is still the case that many fintechs are doing one of two things:
Procuring a commercial solution without thinking about what is going to be logged, or thinking about the actual business goals that a logging solution is intended to achieve.
Just going with the Cloud Service Provider’s (CSP) SaaS offering – e.g. Stackdriver (now called “Operations”) for Google Cloud, or Security Center for Azure.
Design Process
The process HLD takes into risks from threat modelling (and maybe other sources), and another input from compliance requirements (maybe security standards and legal requirements), and uses the requirements from the HLD to drive the LLD. The LLD will call out the use cases and volume requirements that satisfy the HLD requirements – but importantly, it does not cover the technological solution. That comes later.
The diagram above calls out Splunk but of course it doesn’t have to be Splunk.
Security Operations
The end goal of the design process is heavily weighted towards a security operations or protective monitoring capability. Alerts will be specified which will then be configured into the technological solution (if it supports this). Run-books are developed based on on-going continuous improvement – this “tuning” is based on adjusting to false positives mainly, and adding further alerts, or modifying existing alerts.
The decision making on how to respond to alerts requires intimate knowledge of networks and applications, trust relationships, data flows, and the business criticality of information assets. This is not a role for fresh graduates. Risk assessment drives the response to an alert, and the decision on whether or not to engage an incident response process.
General IT monitoring can form the first level response, and then Security Operations consumes events from this first level that are related to potential security incidents.
Two main points relating this SecOps function:
Outsourcing doesn’t typically work when it comes to the 2nd level. Outsourcing of the first level is more likely to be cost effective. Dr Anton Chuvakin’s post on what can, and cannot be outsourced in security is the most well-rounded and realistic that i’ve seen. Generally anything that requires in-house knowledge and intimacy of how events relate to business risks – this cannot be outsourced at all effectively.
The maturity of SecOps doesn’t happen overnight. Expect it to take more than 12 months for a larger fintech with a complex cloud footprint.
The logging capability is the bedrock of SecOps, and how it relates to other security capabilities can be simplified as in the diagram below. The boxes on the left are self-explanatory with the possible exception of Active Trust Management – this is heavily network-oriented and at the engineering end of the rainbow, its about firewalls, reverse and forward proxies mainly:
Custom Use Cases
For the vast majority of cases, custom use cases will need to be formulated. This involves building a picture of “normal”, so as to enable alerting on abnormal. So taking the networking example: what are my data flows? Take my most critical applications – what are source and destination IP addresses, and what is the port on the server-side of the client-server relationship? So then a possible custom use case could be: raise an alert when a connection is aimed at the server from anywhere other than the client(s).
Generic use cases are no-brainers. Examples are brute force attempts and technology or user behaviour-specific use cases. Some good examples are here. Custom use cases requires an understanding of how applications, networks, and operating systems are knitted together. But both custom and generic use cases require a log source to be called out. For network events, this will be a firewall as the best candidate. It generally makes very little sense to deploy network IDS nodes in cloud.
So for each application, generate a table of custom use cases, and identify a log source for each. Generic use cases are those configured auto-tragically in Splunk Enterprise Security for example. But even Splunk cannot magically give you custom use cases, or even ensure that all devices are included in the coverage for generic use cases. No – humans still have a monopoly over custom use cases and well, really, most of SIEM configuration. AI and Cyberdyne Systems won’t be able to get near custom use cases in our lifetimes, or ever, other than the fantasy world of vendor Powerpoint slides.
Don’t forget to test custom use case alerting. So for network events, spin up a VM in a centrally trusted area, like a management Vnet/VPC for example. Port scan from there to see if alerts are triggered. Netcat can be very useful here too, for spoofing source addresses for example.
Correlation
Correlation was the phrase used by vendors in the heady days of the 00s. The premise was something like this: event A, event B, and event C. Taken in isolation (topical), each seem innocuous. But bake them together and you have a clear indicator that skullduggery is afoot.
I suggest you park correlation in the early stage of a logging capability deployment. Maybe consider it for down the road, once a decent level of maturity has been reached in SecOps, and consider also that any attempt to try and get too clever can result in your SIEM frying circuit boards. The aim initially should be to reduce complexity as much as possible, and nothing is better at adding complexity than correlation. Really – basic alerting on generic and custom use cases gives you most of the coverage you need for now, and in any case, you can’t expect to get anywhere near an ideal state with logging.
SaaS
Operating system logs are important in many cases. When you decide to SaaS a solution, note that you lose control over operating system events. You cannot turn off events that you’re not interested in (e.g. Windows Object auditing events which have had a few too many pizzas). This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
Note – its also, in most cases, not such a great idea to use a SaaS based SIEM. Why? Because this function has connectivity with everything. It has trust relationships with dev/test, pre-prod, and production. You really want full control over this platform (i.e. be able to login with admin credentials and take control of the OS), especially as it hosts lots of information that would be very interesting for attackers, and is potentially the main target for attackers, because of the trust relationships I mentioned before.
So with SaaS, its probably not the case that you are missing critical events. You just get flooded. The same applies to 3rd party applications, but for custom, in-house developed applications, you still have control of course of the application layer.
Custom, In-house Developed Applications
You have your debugging stream and you have your application stream. You can assign critical levels to events in your code (these are the classic syslog severity levels). The application events stream is critical. From an application security perspective, many events are not immediately intuitively of interest, but by using knowledge of how hackers work in practice, security can offer some surprises here, pleasant or otherwise.
If you’re a developer, you can ease the strain on your infosec colleagues by using consistent JSON logging keys across the board. For example, don’t start with ‘userid’ and then flip to ‘user_id’ later, because it makes the configuration of alerting more of a challenge than it needs to be. To some extent, this is unavoidable, because different vendors use different keys, but every bit helps. Note also that if search patterns for alerting have to cater for multiple different keys in JSON documents, the load on the SIEM will be unnecessarily high.
It goes without saying also: think about where your application and debug logs are being transmitted and stored. These are a source of extremely valuable intelligence for an attacker.
The Technology
The technological side of the logging capability isn’t the biggest side. The technology is there to fulfil a logging requirement, it is not in itself the logging capability. There are also people and processes around logging, but its worth talking about the technology.
What’s more common than many would think – organisation acquires a COTS SIEM tool but the security engineers hate it. Its slow and doesn’t do much of any use. So they find their own way of aggregating network-centralised events with a syslog bucket of some description. Performance is very often the reason why engineers will be grep’ing over syslog text files.
Whereas the aforementioned sounds ineffective, sadly its more effective than botched SIEM deployments with poorly designed tech. It also ticks the “network centralised logging” box for auditors.
The open-source tools solution can work for lots of organisations, but what you don’t get so easily is the real-time alerting. The main cost will be storage. No license fees. Just take a step back, and think what it is you really want to achieve in logging (see the design process above). The features of the open source logging solution can be something like this:
Rsyslog is TCP and covers authentication of hosts. Rsyslog is a popular protocol because it enables TCP layer transmission from most log source types (one exception is some Cisco network devices and firewalls), and also encryption of data in transit, which is strongly recommended in a wide open, “flat” network architecture where eavesdropping is a prevalent risk.
Even Windows can “speak” rsyslog with the aid of a local agent such as nxlog.
There are plenty of Host-based Intrusion Detection System (HIDS) agents for Linux and Windows – OSSEC, Suricata, etc.
Intermediate network logging Rsyslog servers can aggregate logs for network zones/subnets. There are the equivalent of Splunk forwarders or Alienvault Sensors. A cron job runs an rsync over Secure Shell (SSH), which uploads the batches of events data periodically to a Syslog Lake, for want of a better phrase.
The folder structure on the Syslog server can reflect dates – years, months, days – and distinct files are named to indicate the log source or intermediate server.
Splunk sales people have a dart board with my picture on it. To be fair, the official Splunk line is that they want to help their customers save events indexing money because it benefits them in the longer term. And they’re right, this does work for Splunk and their customers. But many of the resellers are either lacking the skills to help, or they are just interested in a quick and dirty install. “Live for today, don’t worry about tomorrow”.
Splunk really is a Lamborghini, and the few times when i’ve been involved in bidding beauty parades for SIEM, Splunk often comes out cheaper believe it or not. Splunk was made for logging and was engineered as such. Some of the other SIEM engines are poorly coded and connect to a MySQL database for example, whereas Splunk has its own database effectively. The difference in performance is extraordinary. A Splunk search involving a complex regex with busy indexers and search heads takes a fraction of the time to complete, compared with a similar scenario from other tools on the same hardware.
Three main ways to reduce events indexing costs with Splunk:
Root out useless events. Windows is the main culprit here, in particular Auditing of Objects. Do you need, for example, all that performance monitoring data? Debug events? Firewall AND NIDS events? Denied AND accepted packets from firewalls?
You can be highly selective about which events are forwarded to the Splunk indexer. One conceptual model just to illustrate the point is given below:
Threat Hunting
Threat Hunting is kind of the sexy offering for the world of defence. Offence has had more than its fair share of glamour offerings over the years. Now its defence’s turn. Or is it? I mean i get it. It’s a good thing to put on your profile, and in some cases there are dramatic lines such as “be the hunter or the hunted”.
However, a rational view of “hunting” is that it requires LOTS of resources and LOTS of skill – two commodities that are very scarce. Threat hunting in most cases is the worst kind of resources sink hole. If you take vulnerability management (TVM) and the kind of basic detection discussed thus far in this article, you have a defence capability that in most cases fits the risk management needs of the organisation. So then there’s two questions to ask:
How much does threat hunting offer on top of a suitably configured logging and TVM capability? Not much in the best of cases. Especially with credentialed scanning with TVM – there is very little of your attack surface that you cannot cover.
How much does threat hunting offer in isolation (i.e. threat hunting with no TVM or logging)? This is the worst case scenario that will end up getting us all fired in security. Don’t do it!!! Just don’t. You will be wide open to attack. This is similar to a TVM program that consists only of one-week penetration tests every 6 months.
Threat Intelligence (TI)
Ok so here’s a funny story. At a trading house client here in London around 2016: they were paying a large yellow vendor lots of fazools every month for “threat intelligence”. I couldn’t help but notice a similarity in the output displayed in the portal as compared with what i had seen from the client’s Alienvault. There is a good reason for this: it WAS Alienvault. The feeds were coming from switches and firewalls inside the client network, and clearly $VENDOR was using Alienvault also. So they were paying heaps to see a duplication of the data they already had in their own Alienvault.
The aforementioned is an extremely bad case of course. The worst of the worst. But can you expect more value from other threat intelligence feeds? Well…remember what i was saying about the value of an effective TVM and detection program? Ok I’ll summarise the two main problems with TI:
You can really achieve LOTS in defence with a good credentialed TVM program plus even a half-decent logging program. I speak as someone who has lots of experience in unrestricted penetration testing – believe me you are well covered with a good TVM and detection SecOps function. You don’t need to be looking at threats apart from a few caveats…see later.
TI from commercial feeds isn’t about your network. Its about the whole planet. Its like picking up a newspaper to find out what’s happening in the world, and seeing on the front cover that a butterfly in China has flapped its wings recently.
Where TI can be useful – macro developments and sector-specific developments. For example, a new approach to Phishing, or a new class of vulnerability with software that you host, or if you’re in the public sector and your friendly national spy agency has picked up on hostile intentions towards you. But i don’t want to know that a new malware payload has been doing the rounds. In the time taken to read the briefing, 2000 new payloads have been released to the wild.
Summary
Start out with a design process that takes input feeds from compliance and risk (perhaps threat modelling), use the resulting requirements to drive the LLD, which may or may not result in a decision to procure tech that meets the requirements of the LLD.
An effective logging capability can only be designed with intimate knowledge of the estate – databases, crown jewels, data flows – for each application. Without such knowledge, it isn’t possible to build even a barely useful logging capability. Call out your generic and custom use cases in your LLD, independent of technology.
Get your basic alerting first, correlation can come later, if ever.
Outsourcing is a waste of resources for second level SecOps.
With SaaS, your SIEM itself is dangerously exposed, and you have no control over what is logged from SaaS log sources.
You are not mandated to get a COTS. Think about what it is that you want to achieve. It could be that open source tools across the board work for you.
Splunk really is the Lamborghini of SIEMs and the “expensive” tag is unjustified. If you carefully design custom and generic use cases, and remove everything else from indexing, you suddenly don’t have such an expensive logger. You can also aggregate everything in a Syslog pool before it hits Splunk indexers, and be more selective about what gets forwarded.
I speak as someone with lots of experience in unrestricted penetration testing: Threat Hunting and Threat Intelligence aren’t worth the effort in most cases.
Part Two – Threat and Vulnerability Management – Application Security
Part Three – Threat and Vulnerability Management – Other Layers
Part Four – Logging
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Threat and Vulnerability Management (TVM) – Other Layers
This article covers the key principles of vulnerability management for cloud, devops, and devsecops, and herein addresses the challenges faced by fintechs.
Fintechs are focussing on application security, which is good, but not so much in the security of other areas such as containers, IaaS/SaaS VMs, and little thought is ever given to the supply of patches and container images (they need to come from an integral source – preferably not involving pulling from the public Internet, and the patches and images need to be checked for integrity themselves).
And in general with vulnerability assessment (VA), we in infosec are still battling a popular misconception, which after a quarter of a decade is still a popular misconception – and that is the value, or lack of, of unauthenticated scanners such as OpenVAS and Nessus. More on this later.
The Overall Approach
The design process for a TVM capability was covered in Part One. Capabilities are people, process, and technology. They’re not just technology. So the design of TVM is not as follows: stick an OpenVAS VM in a VPC, fill it with target addresses, send the auto-generated report to ops. That is actually how many fintechs see the TVM challenge, or they just see it as being a purely application security show.
So there is a vulnerability reported. Is it a false positive? If not, then what is the risk? And how should the risk be treated? In order to get a view of risk, security professionals with an attack mindset need to know
the network layout and data flows – think from the point of view of an attacker – so for example if a front end web micro-service is compromised, what can the attacker can do from there? Can they install recon tools such as a port scanner or sniffer locally and figure out where the back end database is? This is really about “trust relationships”. That widget that routes connections may in itself seem like a device that isn’t worthy of attention, but it routes connections to a database hosting crown jewels…you can see its an important device and its configuration needs some intense scrutiny.
the location and sensitivity of critical information assets.
The ease and result of an exploit – how easy is it to gain a local shell presence and then what is the impact?
The points above should ideally be covered as part of threat modelling, that is carried out before any TVM capability design is drafted.
if the engineer or analyst or architect has the experience in CTF or simulated attack, they are in a good position to speak confidently about risk.
There are two types: unauthenticated and credentialed or authenticated scanners.
Many years ago i was an analyst running VA scans as part of an APAC regional accreditation service. I was using Nessus mostly but some other tools also. To help me filter false positives, I set up a local test box with services like Apache, Sendmail, etc, pointed Nessus at the box, then used Ethereal (now Wireshark) to figure out what the scanner was actually doing.
What became abundantly obvious with most services, is that the scanner wasn’t actually doing anything. It grabs a service banner and then …nothing.
I thought initially there was a problem with my setup but soon eliminated that doubt. There are a few cases where the scanner probes for more information but those automated efforts are somewhat ineffectual and in many cases the test that is run, and then the processing of the result, show a lack of understanding of the vulnerability. A false negative is likely to result, or at best a false positive. The scanner sees a text banner response such as “apache 2.2.14”, looks in its database for public disclosed vulnerability for that version, then barfs it all out as CRITICAL, red colour, etc.
Trying to assess vulnerability of an IaaS VM with unauthenticated VA scanners is like trying to diagnose a problem with your car without ever lifting the hood/bonnet.
So this leads us to credentialed scanners. Unfortunately the main players in the VA space pander to unauthenticated scans. I am not going to name vendors here, but its clear the market is poorly served in the area of credentialed scanning.
It’s really very likely that sooner rather than later, accreditation schemes will mandate credentialed scanning. It is slowly but surely becoming a widespread realisation that unauthenticated scanners are limited to the above-mentioned testing methodology.
So overall, you will have a set of Technical Security Standards for different technologies such as Linux, Cisco IoS, Docker, and some others. There are a variety of tools out there that will get part of the job done with the more popular operating systems and databases. But in order to check compliance to your Technical Security Standards, expect to have to bridge the gap with your own scripting. With SSH this is infinitely feasible. With Windows, it is harder, but check Ansible and how it connects to Windows with Python.
Asset Management
Before you can assess for vulnerability, you need to know what your targets are. Thankfully Cloud comes with fewer technical barriers here. Of course the same political barriers exist as in the on-premise case, but the on-premise case presents many technical barriers in larger organisations.
Google Cloud has a built-in feature, and with AWS, each AWS Service (eg Amazon EC2, Amazon S3) have their own set of API calls and each Region is independent. AWS Config is highly useful here.
SaaS
I covered this issue in more detail in a previous post.
Remember the old times of on-premise? Admins were quite busy managing patches and other aspects of operating systems. There are not too many cases where a server is never accessed by an admin for more than a few weeks. There were incompatibilities and patch installs often came with some banana skins around dependencies.
The idea with SaaS is you hand over your operating systems to the CSP and hope for the best. So no access to SMB, RDP, or SSH. You have no visibility of patches that were installed, or not (!), and you have no idea which OS services are enabled or not. If you ask your friendly CSP for more information here, you will not get a reply, and if you do they will remind you that handed over your 50-million-lines-of-source-code OSes to them.
Here’s an example – one variant of the Conficker virus used the Windows ‘at’ scheduling service to keep itself prevalent. Now cloud providers don’t know if their customers need this or not. So – they verge on the side of danger and assume that they do. They will leave it enabled to start at VM boot up.
Note that also – SaaS instances will be invisible to credentialed VA scanners. The tool won’t be able to connect to SSH/RDP.
I am not suggesting for a moment that SaaS is bad. The cost benefits are clear. But when you moved to cloud, you saved on managing physical data centers. Perhaps consider that also saving on management of operating systems maybe taking it too far.
The patches need to come from an integral source – this is where DNSSEC can play a part but be aware of its limitations – e.g. update.microsoft.com does not present a ‘dnskey’ Resource Record. Vendors sometimes provide a checksum or PGP cryptogram.
Some vendors do not present any patch integrity checksums at all and will force users to download a tarball. This is far from ideal and a workaround will be critical in most cases.
Redhat has their Satellite Network which will meet most organisations’ requirements.
For cloud, the best approach will usually be to ingress patches to a management VPC/Vnet, and all instances (usually even across differing code maturity level VPCs), can pull from there.
Delta Testing
Doing something like scanning critical networks for changes in advertised listening services is definitely a good idea, if not for detecting hacker shells, then for picking up on unauthorised changes. There is no feasible means to do this manually with nmap, or any other port scanner – the problem is time-outs will be flagged as a delta. Commercial offerings are cheap and allow tracking over long histories, there’s no false positives, and allow you to create your own groups of addresses.
Penetration Testing
There’s ideal state, which for most orgs is going to be something like mature vulnerability management processes (this is vulnerability assessment –> deduce risk with vulnerability –> treat risk –> repeat), and the red team pen test looks for anything you may have missed. Ideally, internal sec teams need to know pretty much everything about their network – every nook and cranny, every switch and firewall config, and then the pen test perhaps tells them things they didn’t already know.
Without these VM processes, you can still pen test but the test will be something like this: you find 40 holes of the 1000 in the sieve. But it’s worse than that, because those 40 holes will be back in 2 years.
There can be other circumstances where the pen test by independent 3rd party makes sense:
Compliance requirement.
Its better than nothing at all. i.e. you’re not even doing VA scans, let alone credentialed scans.
Wrap-up
It’s far from all about application security. This area was covered in part two.
Design a TVM capability (people, process, technology), don’t just acquire a technology (Qualys, Rapid 7, Tenable SC. etc), fill it with targets, and that’s it.
Use your VA data to formulate risk, then decide how to treat the risk. Repeat. Note that CVSS ratings are not particularly useful here. You need to ascertain risk for your environment, not some theoretical environment.
Credentialed scanning is the only solution worth considering, and indeed it’s highly likely that compliance schemes will soon start to mandate credentialed scanning.
Use a network delta tester to pick up on hacker shells and unauthorised changes in network services and firewalls.
Being dynamic with Kubernetes and microservices has not yet killed your platform risk or the OS in general.
SaaS may be a step too far for many, in terms of how much you can outsource.
When you SaaS’ify a service, you hand over the OS to a CSP, and also remove it from the scope of your TVM VA credentialed scanning.
Penetration testing has a well-defined place in security, which isn’t supposed to be one where it is used to inform security teams about their network! Think compliance, and what ideal state looks like here.
Part Two – Threat and Vulnerability Management – Application Security
Part Three – Threat and Vulnerability Management – Other Layers
Part Four – Logging
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Recruiting and Interviews
In the prologue of this four-stage process, I set the scene for what may come to pass in my attempt to relate my experiences with fintechs, based on what i am hearing on the street and what i’ve seen myself. In this next instalment, i look at how fintechs are approaching the hiring conundrum when it comes to hiring security specialists, and how, based on typical requirements, things could maybe be improved.
The most common fintech setup is one of public-cloud (AWS, Azure, GCP, etc), They’re developing, or have developed, software for deployment in cloud, with a mobile/web front end. They use devops tools to deploy code, manage and scale (e.g. Kubernetes), collaborate (Git variants) and manage infrastructure (Ansible, Terraform, etc), perhaps they do some SAST. Sometimes they even have different Virtual Private Clouds (VPCs) for different levels of code maturity, one for testing, and one for management. And third party connections with APIs are not uncommon.
Common Pitfalls
Fintechs adopt the stance: “we don’t need outside help because we have hipsters. They use acronyms and seem quite confident, and they’re telling me they can handle it”. While not impossible that this can work – its unlikely that a few devops peeps can give a fintech the help they need – this will become apparent later.
Using devops staff to interview security engineers. More on this problem later.
Testing security engineers with a list of pre-prepared questions. This is unlikely to not end in tears for the fintech. Security is too wide and deep an area for this approach. Fintechs will be rejecting a lot of good candidates by doing this. Just have a chat! For example, ask the candidate their opinions on the usefulness of VA scanners. The length of the response is as important as its technical accuracy. A long response gives an indication of passion for the field.
Getting on the security bandwagon too late (such as when you’re already in production!) you are looking at two choices – engage an experienced security hand and ignore their advice, or do not ignore their advice and face downtime, and massive disruption. Most will choose the first option and run the project at massive business risk.
The Security Challenge
Infosec is important, just as checking to see if cars are approaching before crossing the road is important. And the complexity of infosec mandates architecture. Civil engineering projects use architecture. There’s a good reason for that – which doesn’t need elaborating on.
Whenever you are trying to build something complex with lots of moving parts, architecture is used to reduce the problem down to a manageable size, and help to build good practices in risk management. The end goal is protective monitoring of an infrastructure that is built with requirements for meeting both risk and compliance challenges.
Because of the complexity of the challenge, it’s good to split the challenge into manageable parts. This doesn’t require talking endlessly about frameworks such as SABSA. But the following six capabilities (people, process, technology) approach is sleek and low-footprint enough for fintechs:
Threat and Vulnerability Management (TVM)
Logging – not “telemetry” or Threat intelligence, or threat hunting. Just logging. Not even necessarily SIEM.
Cryptography and Key Management
Identity Management
Business Continuity Management
Trust (network segmentation, firewalls, proxies).
I will cover these 6 areas in the next two articles, in more detail.
The above mentioned capabilities have an engineering and architecture component and cover very briefly the roles of security engineers and architects. A SABSA based approach without the SABSA theory can work. So an architect takes into account risk (maybe with a threat modelling approach) and compliance goals in a High Level Design (HLD), and generates requirements for the Low Level Design (LLD), which will be compiled by a security engineer. The LLD gives a breakdown of security controls to meet the requirements of the HLD, and how to configure the controls.
Security Engineers and Devops Tools
What happens when a devops peep interviews a security peep? Well – they only have their frame of reference to go by. They will of course ask questions about devops tools. How useful is this approach? Not very. Is this is good test of a security engineer? Based on the security requirements for fintechs, the answer is clear.
Security engineers can use devops tools, and they do, and it doesn’t take a 2 week training course to learn Ansible. There is no great mystery in Kubernetes. If you hire a security engineer with the right background (see the previous post in this series) they will adapt easily. The word on the street is that Terraform config isn’t the greatest mystery in the world and as long as you know Linux, and can understand what the purpose of the tool is (how it fits in, what is the expected result), the time taken to get productive is one day or less.
The point is: if i’m a security engineer and i need to, for example, setup a cloud SIEM collector: some fintechs will use one Infrastructure As Code (IaC) tool, others use another one – one will use Chef, another Ansible, and there are other permutations. Is a lack of familiarity with the tool a barrier to progress? No. So why would you test a security engineer’s suitability for a fintech role by asking questions about e.g. stanzas in Ansible config? You need to ask them questions about the six capabilities I mentioned above – i.e. security questions for a security professional.
Security Engineers and Clouds
Again – what was the transition period from on-premise to cloud? Lets take an example – I know how networking works on-premise. How does it work in cloud? There is this thing called a firewall on-premise. In Azure it’s called a Network Security Group. In AWS its called a …drum roll…firewall. In Google Cloud its called a …firewall. From the web-based portal UI for admin, these appear to filter by source and destination addresses and services, just like an actual non-virtual firewall. They can also filter by service account (GCP), or VM tag.
There is another thing called VPN. And another thing called a Virtual Router. On the world of on-premise, a VPN is a …VPN. A virtual router is a…router. There might be a connection here!
Cloud Service Providers (CSP) in general don’t re-write IT from the ground up. They still use TCP/IP. They host virtual machines (VM) instead of real machines, but as VMs have operating systems which security engineers (with the right background) are familiar with, where is the complication here?
The areas that are quite new compared to anything on-premise are areas where the CSP has provided some technology for a security capability such as SIEM, secrets management, or Identity Management. But these are usually sub-standard for the purpose they were designed for – this is deliberate – the CSPs want to work with Commercial Off The Shelf (COTS) vendors such as Splunk and Qualys, who will provide a IaaS or SaaS solution.
There is also the subject of different clouds. I see some organisations being fussy about this, e.g. a security engineer who worked a lot with Azure but not AWS, is not suitable for a fintech that uses AWS. Apparently. Well, given that the transition from on-premise to cloud was relatively painless, how painful is it to transition from Azure to AWS or …? I was on a project last summer where the fintech used Google Cloud Platform. It was my first date with GCP but I had worked with AWS and Azure before. Was it a problem? No. Do i have an IQ of 160? Hell no!
The Wrap-up
Problems we see in fintech infosec hiring represent what is most likely a lack of understanding of how they can best manage risk with a budget that is considerably less than a large MNC for example. But in security we haven’t been particularly helpful for fintechs – the problem is on us.
The security challenge for fintechs is not just about SAST/DAST of their code. The challenge is wider and be represented as six security capabilities that need to be designed with an architecture and engineering view. This sounds expensive, but its a one-off design process that can be covered in a few weeks. The on-going security challenge, whereby capabilities are pushed through into the final security operations stage, can be realised with one or two security engineers.
The lack of understanding of requirements in security leads to some poor hiring practices, the most common of which is to interview a security engineer with a devops guru. The fintech will be rejecting lots of good security engineers with this approach.
In so many ways, the growth of small to medium development houses has exposed the weaknesses in the infosec sector more than they were ever exposed with large organisations. The lack of the sector’s ability to help fintechs exposes a fundamental lack of skilled personnel, more particularly at the strategic/advisory level than others.
Part Two – Threat and Vulnerability Management – Application Security
Part Three – Threat and Vulnerability Management – Other Layers
Part Four – Logging
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Fintechs and Security – A Match Made In Heaven?
Well, no. Far from it actually. But again, as i’ve been repeating for 20 years now, its not on the fintechs. It’s on us in infosec, and infosec has to take responsibility for these problems in order to change. If i’m a CTO of a fintech, I would be confused at the array of opinions and advice which vary radically from one expert to another
But there shouldn’t be such confusion with fintech challenges. Confusion only reigns where there’s FUD. FUD manifests itself in the form of over-lengthy coverage and excessive focus on “controls” (the archetypal shopping list of controls to be applied regardless of risk – expensive), GRC, and “hacking/”[red,blue,purple,yellow,magenta/teal/slate grey] team”/”appsec.
Really what’s needed is something like this (in order):
Threat modelling lite – a one off, reviewed periodically.
Architecture lite – a one off, review periodically.
Engineering lite – a one off, review periodically.
Secops lite – the result of the previous 3 – an on-going protective monitoring capability, the first level of monitoring and response for which can be outsourced to a Managed Service Provider.
I will cover these areas in more details in later episodes but what’s needed is, for example, a security design that only provides the answer to “What is the problem? How are we going to solve it?” – so a SIEM capability design for example – not more than 20 pages. No theory. Not even any justifications. And one that can be consumed by non-security folk (i.e. it’s written in the language of business and IT).
Fintechs and SMBs – How Is The Infosec Challenge Unique?
With a lower budget, there is less room for error. Poor security advice can co-exist with business almost seamlessly in the case of larger organisations. Not so with fintechs and Small and Medium Businesses (SMBs). There has been cases of SMBs going under as a result of a security incident, whereas larger businesses don’t even see a hit on their share price.
Look For A Generalist – They Do Exist!
The term “generalist” is seen as a four-letter word in some infosec circles. But it is possible for one or two generalists to cover the needs of a fintech at green-field, and then going forward into operations, its not unrealistic to work with one in-house security engineer of the right background, the key ingredients of which are:
Spent at least 5 years in IT, in a complex production environment, and outgrew the role.
Has flexibility – the old example still applies today – a Unix fan has tinkered with Windows. So i.e. a technology lover. One who has shown interest in networking even though they’re not a network engineer by trade. Or one who sought to improve efficiency by automating a task with shell scripting.
Has an attack mindset – without this, how can they evaluate risk or confidently justify a safeguard?
I have seen some crazy specialisations in larger organisations e.g. “Websense Security Engineer”! If fintechs approached security staffing in the same way as larger organisations, they would have more security staff than developers which is of course ridiculous.
So What’s Next?
In “On Hiring For DevSecOps” I covered some common pitfalls in hiring and explained the role of a security engineer and architect.
There are “fallback” or “retreat” positions in larger organisations and fintechs alike, wherein executive decisions are made to reduce the effort down to a less-than-advisable position:
Larger organisations: compliance driven strategy as opposed to risk based strategy. Because of a lack of trustworthy security input, execs end up saying “OK i give up, what’s the bottom line of what’s absolutely needed?”
Fintechs: Application security. The connection is made with application development and application security – which is quite valid but the challenge is wider. Again, the only blame i would attribute here is with infosec. Having said that, i noticed this year that “threat modelling” has started to creep into job descriptions for Security Engineers.
So for later episodes – of course the areas to cover in security are wider than appsec, but again there is no great complication or drama or arm-waiving:
Part One – Hiring and Interviews – I expand on “On Hiring For DevSecOps“. I noticed some disturbing trends in 2019 and i cover these in some more detail.
Part Two – Security Architecture and Engineering I – Threat and Vulnerability Management (TVM)
Part Three – Security Architecture and Engineering II – Logging (not necessarily SIEM). No Threat Hunting, Telemetry, or Threat “Intelligence”. No. Just logging. This is as sexy as it needs to be. Any more sexy than this should be illegal.
Part Four – Security Architecture and Engineering III – Identity Management (IDAM) and Cryptography and Key Management (CKM).
Part Five – Security Architecture and Engineering IV – Trust (network trust boundary controls – e.g. firewalls and forward proxies), and Business Resilience Management (BRM).
I will try and get the first episode on hiring and interviewing out before 2020 hits us but i can’t make any promises!
Based on personal experience, and second hand reports, there’s still some confusion out there that results in lots of wasted time for job seekers, hiring organisations, and recruitment agents.
There is a want or a need to blame recruiters for any hiring difficulties, but we need to stop that. There are some who try to do the right thing but are limited by a lack of any sector experience. Others have been inspired by Wolf Of Wall Street while trying to sound like Simon Cowell.
It’s on the hiring organisation? Well, it is, but let’s take responsibility for the problem as a sector for a change. Infosec likes to shift responsibility and not take ownership of the problem. We blame CEOs, users, vendors, recruiters, dogs, cats, “Russia“, “China” – anyone but ourselves. Could it be we failed as a sector to raise awareness, both internally and externally?
So What Are Common Understandings Of Security Roles?
After 25 years+ we still don’t have universally accepted role descriptions, but at least we can say that some patterns are emerging. Security roles involve looking at risk holistically, and sometimes advising on how to deal with risk:
Security Engineers assess risk and design and sometimes also implement controls. BTW some sectors, legal in particular, still struggle with this. Someone who installs security products is in an IT ops role. Someone who upgrades and maintains a firewall is an IT ops role. The fact that a firewall is a security control doesn’t make this a security engineering function.
Security Architects take risk and compliance goals into account when they formulate requirements for engineers.
Security Analysts are usually level 2 SOC analysts, who make risk assessments in response to an alert or vulnerability, and act accordingly.
This subject evokes as much emotion as CISSP. There are lots of opinions out there. We owe to ourselves to be objective. There are plenty of sources of information on these role definitions.
No Aspect Of Risk Assessment != Security. This is Devops.
If there is no aspect of risk involved with a role, you shouldn’t looking for a security professional. You are looking for DEVOPS peeps. Not security peeps.
If you want a resource to install and configure tools in cloud – that is DEVOPS. It is not Devsecops. It is not Security Engineering or Architecture. It is not Landscape Architecture or Accounting. It is not Professional Dog Walker. it is DEVOPS. And you should hire a DEVOPS person. If you want a resource to install and configure appsec tools for CI/CD – that is DEVOPS. If you want a resource to advise on or address findings from appsec tools, that is a Security Analyst in the first case, DEVSECOPS in the 2nd case. In the 2nd case you can hire a security bod with coding experience – they do exist.
Ok Then So What Does A DevSecOps Beast Look Like?
DevSecOps peeps have an attack mindset from their time served in appsec/pen testing, and are able to take on board the holistic view of risk across multiple technologies. They are also coders, and can easily adapt to and learn multiple different devops tools. This is not a role for newly graduated peeps.
Doing Security With Non-Security Professionals Is At Best Highly Expensive
Another important point: what usually happens because of the skills gap in infosec:
Cloud: devops fills the gap.
On-premise: Network Engineers fill the gap.
Why doesn’t this work? I’ve met lots of folk who wear the aforementioned badges. Lots of them understand what security controls are for. Lots of them understand what XSS is. But what none of them understand is risk. That only comes from having an attack mindset. The result will be overspend usually – every security control ever conceived by humans will be deployed, while also having an infrastructure that’s full of holes (e.g. default install IDS and WAF is generally fairly useless and comes with a high price tag).
Vulnerability assessment is heavily impacted by not engaging security peeps. Devops peeps can deploy code testing tools and interpret the output. But a lack of a holistic view or an attack mindset, will result in either no response to the vulnerability, or an excessive response. Basically, the Threat And Vulnerability Management capability is broken under these circumstances – a sadly very common scenario.
SIEM/Logging is heavily impacted – what will happen is either nothing (default logging – “we have Stackdriver, we’re ok”), or a SIEM tool will be provisioned which becomes a black hole for events and also budgets. All possible events are configured from every log source. Not so great. No custom use cases will be developed. The capability will cost zillions while also not alerting when something bad is going down.
Identity Management – is not deploying a ForgeRock (please know what you’re getting into with this – its a fork of Sun Microsystems/Oracle’s identity management show) or an Azure AD and that’s it, job done. If you just deploy this with no thought of the problem you’re trying to solve in identity management, you will be fired.
One of the classic risk problems that emerges when no security input is taken: “there is no personally identifiable information in development Virtual Private Clouds, so there is no need for security controls”. Well – intelligence vulnerability such as database schema – attackers love this. And don’t you want your code to be safe and available?
You see a pattern here. It’s all or nothing. Either of which ends up being very expensive or worse. But actually come to think of it, expensive is the goal in some cases. Hold that thought maybe.
A Final Word
So – if the word risk doesn’t appear anywhere in the job description, it is nothing to do with security. You are looking for devops peeps in this case. And – security is an important consideration for cloud migrations.
Recently the venerable Brian Krebs covered a mass-DNS hijacking attack wherein suspected Iranian attackers intercepted highly sensitive traffic from public and private organisations. Over the course of the last decade, DNS issues such as cache poisoning and response/request hijacking have caused financial headaches for many organisations.
Wired does occasionally dip into the world of infosec when there’s something major to cover, as they did here, and Arstechnica published an article in January this year that quotes warnings about DNS issues from Federal authorities and private researchers. Interestingly DNSSEC isn’t covered in either of these.
The eggheads behind the Domain Name System Security Extensions (obvious really – you could have worked that out from the use of ‘DNSSEC’) are keeping out of the limelight, and its unknown as to exactly how DNSSEC was conceived, although if you like RFCs (and who doesn’t?) there is a strong clue from RFC 3833 – 2004 was a fine year for RFCs.
The idea that responses from DNS servers may be untrustworthy goes way back, indeed the Council of Elrond behind RFC 3833 called out the year 1993 as being the one where the discussion on this matter was introduced, but the idea was quashed – the threats were not clearly seen in the early 90s. An even more exploitable issue was around lack of access control with networks, but the concept of private networks with firewalls at choke points was far from widespread.
DNSSEC Summarised
For a well-balanced look at DNSSEC, check Cloudfare’s version. Here’s the headline paragraph which serves as a decent summary “DNSSEC creates a secure domain name system by adding cryptographic signatures to existing DNS records. These digital signatures are stored in DNS name servers alongside common record types like A, AAAA, MX, CNAME, etc. By checking its associated signature, you can verify that a requested DNS record comes from its authoritative name server and wasn’t altered en-route, opposed to a fake record injected in a man-in-the-middle attack.”
DNSSEC Gripes
There is no such thing as a “quick look” at a technical coverage of DNSSEC. There is no “birds eye view” aside from “it’s used for DNS authentication”. It is complex – so much so that’s it’s amazing that it even works at all. It is PKI-like in its complexity but PKIs do not generally live almost entirely on the Public Internet – the place where nothing bad ever happened and everything is always available.
The resources required to make DNSSEC work, with key rotation, are not negligible. A common scenario – architecture designs call out a requirement for authentication of DNS responses in the HLD, then the LLD speaks of DNSSEC. But you have to ask yourself – how do client-side resolvers know what good looks like? If you’re comparing digital signatures, doesn’t that mean that the client needs to know what a good signature is? There’s some considerable work needed to get, for example, a Windows 10/Server 2k12 environment DNSSEC-ready: client side configuration.
DNSSEC is far from ubiquitous. Indeed – here’s a glaring example of that:
So, maybe i’m missing something, but i’m not seeing any Resource Records for DNSSEC here. And that’s bad, especially when threat modelling tells us that in some architectures, controls can be used to mitigate risk with most attack vectors, but if WSUS isn’t able to make a call on whether or not its pulling patches from an authentic source, this opens the door for attackers to introduce bad stuff into the network. DNSSEC isn’t going to help in this case.
Don’t forget key rotation – DNSSEC is subject to key management. The main problem with Cryptography in the business world has been less about brute-forcing keys and exploiting algorithm weaknesses than is has been about key management weaknesses – keys need to be stored, rotated, and transported securely. Here’s an example of an epic fail in this area, in this case with the NSA’s IAD site. The page linked to by that tweet has gone missing.
For an organisation wishing to authenticate DNS responses, DNSSEC really does have to be ubiquitous – and that can be a challenge with mobile/remote workers. In the article linked above from Brian Krebs, the point was made that the two organisations involved are both vocal proponents and adopters of DNSSEC, but quoting from Brian’s article: “On Jan. 2, 2019 — the same day the DNSpionage hackers went after Netnod’s internal email system — they also targeted PCH directly, obtaining SSL certificates from Comodo for two PCH domains that handle internal email for the company. Woodcock said PCH’s reliance on DNSSEC almost completely blocked that attack, but that it managed to snare email credentials for two employees who were traveling at the time. Those employees’ mobile devices were downloading company email via hotel wireless networks that — as a prerequisite for using the wireless service — forced their devices to use the hotel’s DNS servers, not PCH’s DNNSEC-enabled systems.”
Conclusion
Organisations do need to take DNS security more seriously – based on what i’ve seen most are not even logging DNS queries and answers, occasionally even OS and app layer logs are AWOL on the servers that handle these requests (these are typically serving AD to the organisation in a MS Windows world!).
But we do need DNS. The alternative is manually configuring IP addresses in a load balanced and forward-proxied world where the Origin IP address of web services isn’t at all clear. We are really back in pen and paper territory if there’s no DNS. And there’s also no real, planet earth alternative to DNSSEC.
DNSSEC does actually work as it was intended and its a technically sound concept, and as in Brian’s article, it has thwarted or delayed attacks. It comes with the management costs of any key management system, and relies on private and public organisations to DNSSEC-ize themselves (as well as manage their keys).
While I regard myself an advocate of DNSSEC deployment, it’s clear there are legitimate criticisms of DNSSEC. But we need some way of authentication of answers we receive from public DNS servers. DNSSEC is a key management system that works in principle.
If the private sector applies enough pressure, we won’t be seeing so many articles about either DNS attacks or DNSSEC, because it will be one of those aspects of engineering that has been addressed and seen as a mandatory aspect of security architecture.
The now infamous WannaCryRansomware outbreak was the most widespread malware outbreak since the early 2000s. There was a very long gap between the early 2000s “worm” outbreaks (think Sasser, Blaster, etc) and this latest 2017 WannaCry outbreak. The usage of the phrase “worm” was itself widespread, especially as it was included in CISSP exam syllabuses, but then it died out. Now its seeing a resurgence, that started last weekend – but why? Why is the worm turning for the worm (I know – it’s bad – but it had to go in here somewhere)?
As far as WannaCry goes, there has been some interesting developments over the past few days – contrary to popular belief, it did not affect Windows XP, the most commonly affected was Windows 7, and according to some experts, the leading suspect in the case is the Lazarus group with ties to North Korea.
But this post is not about WannaCry. I’m going to say it: I used WannaCry to get attention (and with this statement i’m already more honest than the numerous others who jumped on the WannaCry bandwagon, including our beloved $VENDOR). But I have been meaning to cover the rise and fall of the firewall for some time now, and this instance of a widespread and damaging worm, that spreads by exploiting poor firewall configurations, brought this forward by a few months.
A worm is malware that “uses a computer network to spread itself, relying on security failures on the target computer”. If we think of malware delivery and propagation as two different things – lots of malware since 2004 used email (think Phishing) as a delivery mechanism but spread using an exploit once inside a private network. Worms use network propagation to both deliver and spread. And that is the key difference. WannaCry is without doubt a Worm. There is no evidence to suggest WannaCry was delivered on the back of successful Phishing attacks – as illustrated by the lack of WannaCry home user victims (who sit behind the protection of NAT’ing home routers). Most of the early WannaCry posts were covering Phishing, mostly because of the lack of belief that Server Message Block ports would never be exposed to the public Internet.
The Infosec sector is really only 20 years old in terms of the widespread adoption of security controls in larger organisations. So we have only just started to have a usable, relatable history in infosec. Firewalls are still, in 2017, the security control that delivers most value for investment, and they’ve been around since day one. But in the past 20 years I have seen firewall configurations go thru a spectacular rise in the early 2000s, to a spectacular fall a decade later.
Late 90s Firewall
If we’re talking late 90s, even with some regional APAC banks, you would see huge swaths of open ports in port scan results. Indeed, a firewall to many late 90s organisations was as in the image to the left.
However – you can ask a firewall what it is, even a “Next Gen” firewall, and it will answer “I’m a firewall, i make decisions on accepting or rejecting packets based on source and destination addresses and services”. Next Gen firewall vendors tout the ability of firewalls to do layer 7 DPI stuff such as IDS, WAF, etc, but from what I am hearing, many organisations don’t use these features for one reason or another. Firewalls are quite a simple control to understand and organisations got the whole firewall thing nailed quite early on in the game.
When we got to 2002 or so, you would scan a perimeter subnet and only see VPN and HTTP ports. Mind you, egress controls were still quite poor back then, and continue to be lacking to the present day, as is also the case with internal firewalls other than a DMZ (if there are any). 2002 was also the year when application security testing (OWASP type vulnerability testing) took off, and I doubt it would ever have evolved into a specialised area if organisations had not improved their firewalls. Ultimately organisations could improve their firewalls but they still had to expose web services to the planet. As Marcus Ranum said, when discussing the “ultimate firewall”, “You’ll notice there is a large hole sort of in the centre [of the ultimate firewall]. That represents TCP Port 80. Most firewalls have a big hole right about there, and so does mine.”
During testing engagements for the next decade, it was the case that perimeter firewalls would be well configured in the majority of cases. But then we entered an “interesting” period. It started for me around 2012. I was conducting a vulnerability scan of a major private infrastructure facility in the UK…and “what the…”! RDP and SMB vulnerabilities! So the target organisation served a vital function in national infrastructure and they expose databases, SMB, and terminal services ports to the planet. In case there’s any doubt – that’s bad. And since 2012, firewall configs have fallen by the wayside.
WannaCry is delivered and spreads using a SMB vulnerability, as did Blaster and Sasser all those years ago. If we look at Shodan results for Internet exposure of SMB we find 1.5 million cases. That’s a lot.
So how did we get here? Well there are no answers born out of questionnaires and research but i have my suspicions:
All the talk of “Next Generation” firewalls and layer 7 has led to organisations taking their eye off the ball when it comes to layer 3 and 4.
All the talk of magic $VENDOR snake oil silver bullets in general has led organisations away from the basics. Think APT-Buster ™.
Talk of “distortion” of the perimeter (as in “in this age of mobile workforces, where is our perimeter now?”). Well the perimeter is still the perimeter – the clue is in the name. The difference is now there are several perimeters. But WannaCry has reminded us that the old perimeter is still…yes – a perimeter.
There are even some who advocated losing the firewall as a control, but one of the rare success stories for infosec was the subsequent flaming of such opinions. BTW when was that post published? Yes – it was 2012.
So general guidelines:
The Internet is an ugly place with lots of BOTs and humans with bad intentions, along with those who don’t intend to be bad but just are (I bet there are lots of private org firewall logs which show connection attempts of WannaCry from other organisations).
Block incoming for all ports other than those needed as a strict business requirement. Default-deny is the easiest way to achieve this.
Workstations and mobile devices can happily block all incoming connections in most cases.
Other pitfalls with firewalls involve poor usage of NAT and those pesky network dudes who like to bypass inner DMZ firewalls with dual homing.
Watch out for connections from any internal subnet from which human-used devices derive to critical infrastructure such as databases. Those can be blocked in most cases.
Don’t focus on WannaCry. Don’t focus on Ransomware. Don’t focus on malware. Focus on Vulnerability Management.
So then perimeter firewall configurations, it seems, go through the same cycles that economies and seasonal temperature variations go through. When will the winter pass for firewall configurations?
“OK I admit we can’t make cybersecurity great again, because it never was great in the first place”.
It was certainly better than it is now. At one point in time, we had the technical folk, but not the managers. Now we have neither. There was a brain drain from security around the early 2000s whereby tech folk left in droves, either voluntarily or ‘as a business need’. They were seen as aesthetically unpleasing at a time where the perception was that a threat did not exist! In the proceeding years risks increased on the top of the aforementioned shedding of intellectual capital from organisations. Then around 2010 things reached boiling point when security incidents found their way back on the front pages of the Financial Times.
So around 2010 some organisations wanted to get ‘tech’ again but since all the skills were lost 10 years ago, who knows what good looks like? The same folk who inherited the kingdom of security with their fine aesthetics were now charged with finding the skills, while not knowing what the skills look like.
“President Trump recently appointed Rudy Giuliani as cybersecurity adviser. Some reacted to this as a joke”. I would agree that this reaction is short sighted.
“Well me and my colleagues are in industry and we see the issues every day, we are the consultants, the IT auditors, systems administrators, security managers and network engineers. No we are not CEOs or business owners but it’s our job to educate and inform these business leaders of the risk of doing business on the internet. Sometimes they listen and too often they don’t seem to hear us”. All you can do is confidently state your case and get it in writing somewhere. But be aware that confidence should never be faked. Either learn the skills necessary FAST, or find another vocation. C-levels can detect BS ladies and gentlemen and the more of you that try to BS a C-level, the harder you’re making it for the rest of us. Ask yourselves why it is that security was once a board level thing and now most security chiefs reports to a CIO or COO.
“I see this every day as I travel across Florida doing IT audits and assessments. The organizations with a security role funded do 90 percent better than those with no such funded position.” Audits are a poor way of assessing the performance of security. Really poor in fact. Although it can be said that if an audit is failed – that’s uber bad, but if an audit is passed it does not mean all is good.
“One of the problems of the Internet is that we didn’t install what I like to call strong user authentication or strong file authentication.” Yes, we did. Its called an Operating System. For the most part the security sector has shied away from the OS because its hard for folk who don’t have an IT background to understand. Infosec would like to convince decision makers that it doesn’t exist, because if it does exist, then vendors can’t sell many of the snake oil offerings, and non-tech infosec folk are in a vulnerable position.
Operating Systems come with a slew of controls that can be used to thwart and/or detect attacks – perhaps it would be good if we started using them and reporting on how effectively the organisation uses each control? Why spend extra on snake oil products? For example, why spend gazillions on identity management in cloud deployments when we already have it?
“All too often we see organizations relegating cyber security to the IT department. I have said this a hundred times, cybersecurity is a business problem not an IT issue”. This statement suits a certain agenda that plays to the non-tech/GRC oriented folk. Security is a business problem AND an IT problem, but in terms of the intellectual capital required, its 10% a business problem, and 90% an IT problem.
“All users need awareness training” – yes, i think we are now at the stage where security has to be something that is everyone’s responsibility in the same way as checking for cars before crossing the road is everyone’s responsibility.
Infosec is in dire straits because of the loss of critical skills from the sector, and now we have a situation where people with the wrong skills are reporting to the likes of Rudy Giuliani with a lack of confidence and a myriad of confused messages, mostly built around self-serving interests at the expense of the whole. Its likely the former mayor of NY won’t be any wiser as to the scale of the problem, and therefore how to solve it.
Security professionals with no IT background are like animals handlers who are afraid of animals, and its these folk who are representing the sector.
The message that will be delivered to Giuliani will include the part that the sector needs more money. You know it really doesn’t – it needs less. Stop spending money on “next gen” products where “old gen” gets it done. “Legacy” stuff isn’t legacy unless you allow yourself to be duped by vendors into believing that its legacy. Really firewalls and OS offer most of what’s needed.
As Upton Sinclair said “It is difficult to get a man to understand something, when his salary depends on his not understanding it.” This quote lends itself to the problems in information security more than any other sector. Moreover it has defined information security as a broken entity since it was first adopted seriously by banks and then others.
In the world of Clouds and Vulnerability Management, based on observations, it seems like a critical issue has slipped under the radar: if you’re running with PaaS and SaaS VMs, you cannot deliver anything close to a respectable level of vulnerability management with these platforms. This is because to do effective vulnerability management, the first part of that process – the vulnerability assessment – needs to be performed with administrative access (over SSH/SMB), and with PaaS and SaaS, you do not, as a customer, have such access (this is part of your agreement with the cloud provider). The rest of this article explains this issue in more detail.
The main reason for the clouding (sorry) of this issue, is what is still, after 20+ years, a fairly widespread lack of awareness of the ineffectiveness of unauthenticated vulnerability scanning. More and more security managers are becoming aware that credentialed scans are the only way to go. However, with a lack of objective survey data available, I can only draw on my own experiences. See – i’m one of those disgraceful contracting/consultant types, been doing security for almost 20 years, and been intimate with a good number of large organisations, and with each year that passes I can say that more organisations are waking up to the limitations of unauthenticated scanning. But there are also still lots more who don’t clearly see the limitations of unauthenticated scanning.
The original Nessus from the late 90s, now with Tenable, is a great product in terms of doing what it was intended to do. But false negatives were never a concern in with the design of Nessus. OpenVAS is still open source and available and it is also a great tool from the point of view of doing what it was intended to do. But if these tools are your sole source of vulnerability data, you are effectively running blind.
By the way Tenable do offer a product that covers credentialed scans for enterprises, but i have not had any hands-on experience with this tool. I do have hands on experience with the other market leaders’ products. By in large they all fall some way short but that’s a subject for another day.
Unauthenticated scanners all do the same thing:
port scan to find open ports
grab service banners – this is the equivalent of nmap -sV, and in fact as most of these tools use nmap libraries, is it _exactly_ that
lets say our tool finds Apache HTTP 14.x, it looks in its database of public disclosed vulnerability with that version of Apache, and spews out everything it finds. The tools generally do little in the way of actually probing with HTTP Methods for example, and they certainly were not designed to try, for example, a buffer overflow exploit attempt. They report lots of ‘noise’ in the way of false positives, but false negatives are the real concern.
So really the tools are doing a port scan, and then telling you you’re running old warez. Conficker is still very widespread and is the ultimate player in the ‘Pee’ arena (the ‘Pee’ in APT). An unauthenticated scanner doesn’t have enough visibility ‘under the hood’ to tell you if you are going to be the next Conficker victim, or the next ransomware victim. Some of the Linux vulnerabilities reported in the past few years – e.g. Heartbleed, Ghost, DirtyCOW – very few can be detected with an unauthenticated scanner, and none of these 3 examples can be detected with an unauthenticated scanner.
Credentialed scanning really is the only way to go. Credentialed based scanners are configured with root/administrative access to targets and are therefore in a position to ‘see’ everything.
The Connection With PaaS and SaaS
So how does this all relate to Cloud? Well, there two of the three cloud types where a lack of access to the operating system command shell becomes a problem – and from this description its fairly clear these are PaaS and SaaS.
There are two common delusions abound in this area:
[Cloud maker] handles platform configuration and therefore vulnerability for me, so that’s ok, no need to worry:
Cloud makers like AWS and Azure will deal with patches, but concerns in security are much wider and operating systems are big and complex. No patches exist for 0days, and in space, nobody can hear you scream.
Many vulnerabilities arise from OS configuration aspects that cannot be removed with a patch – e.g. Conficker was mentioned above: some Conficker versions (yes its managed very professionally) use ‘at’ job scheduling to remain present even after MS08-067 is patched. If for example you use Azure, Microsoft manage your PaaS and SaaS but they don’t know if you want to use ‘at’ or not. Its safer for them to assume that you do want to use it, so they leave it enabled (when you sign up for PaaS or SaaS you are removed from the decision making here). Same applies to many other local services and file system permissions that are very popular with the dark side.
‘Unauthenticated scanning gets me some of the way, its good enough’ – how much of the way does it get you? Less than half way? its more like 5% really. Remember its little more than a port scan, and you shouldn’t need a scanner to tell you you’re running old software. Certainly for critical cloud VMs, this is a problem.
With PaaS and SaaS, you are handing over the management of large and complex operating systems to cloud providers, who are perfectly justified, and also in many cases perfectly wise, in leaving open large security holes in your platforms, and as part of your agreement with them, there’s not a thing you can do about it (other than switch to IaaS or on-premise).

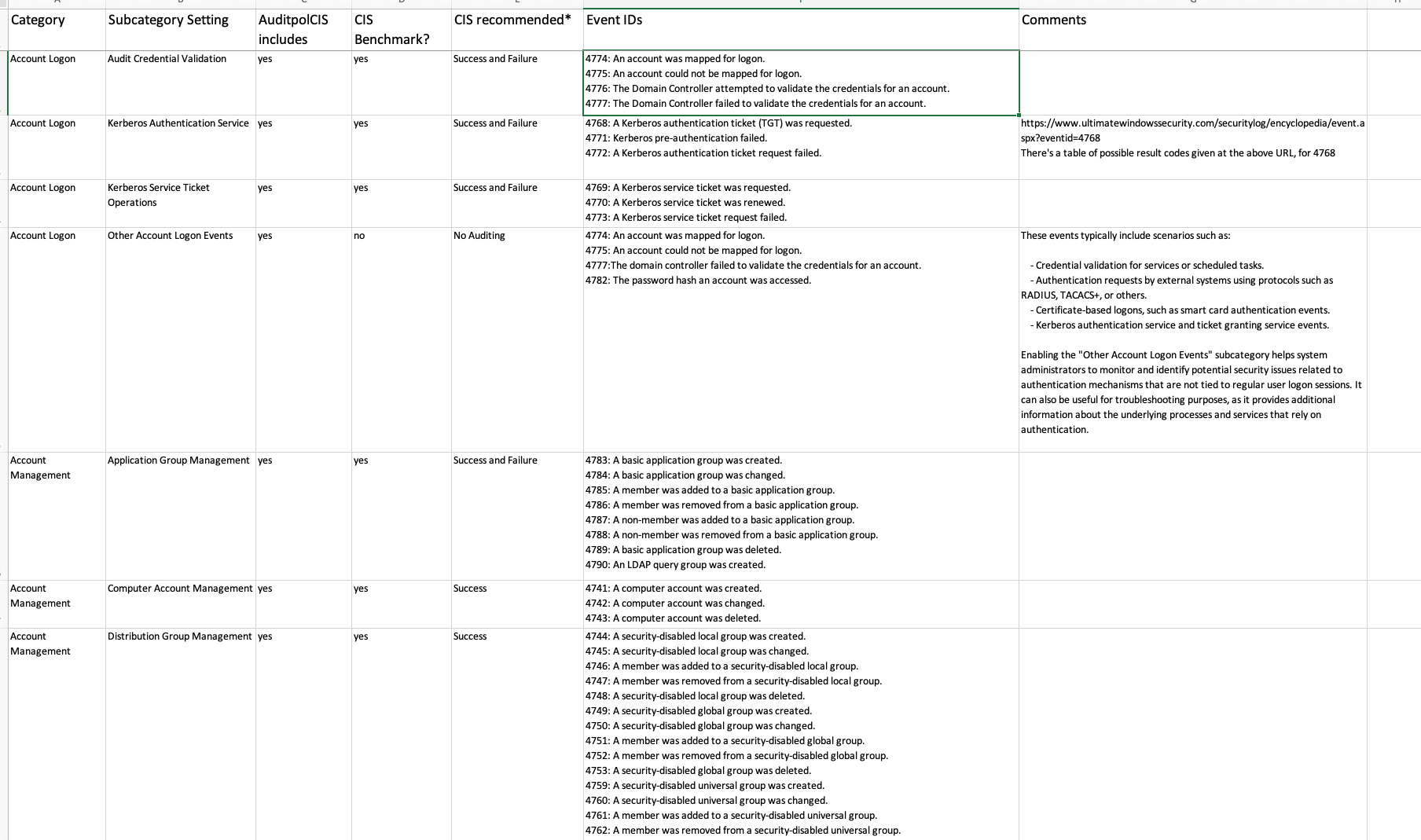

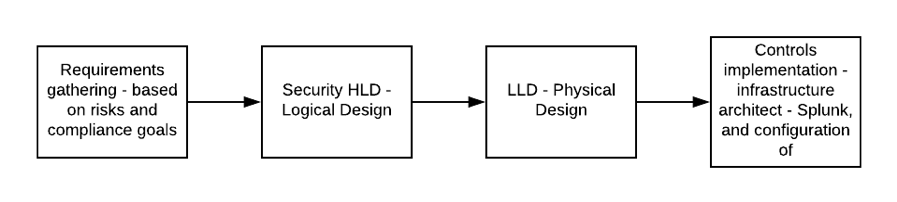
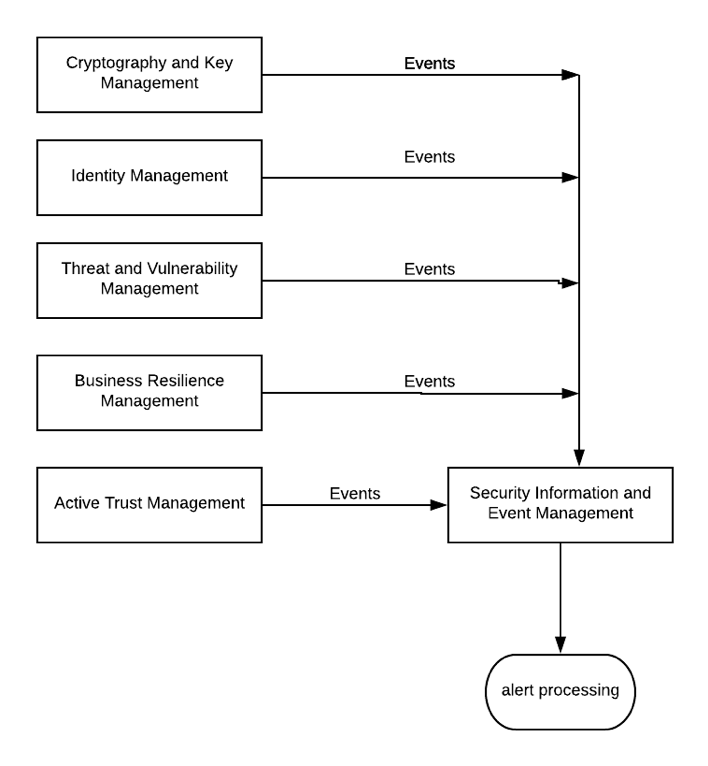
 This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.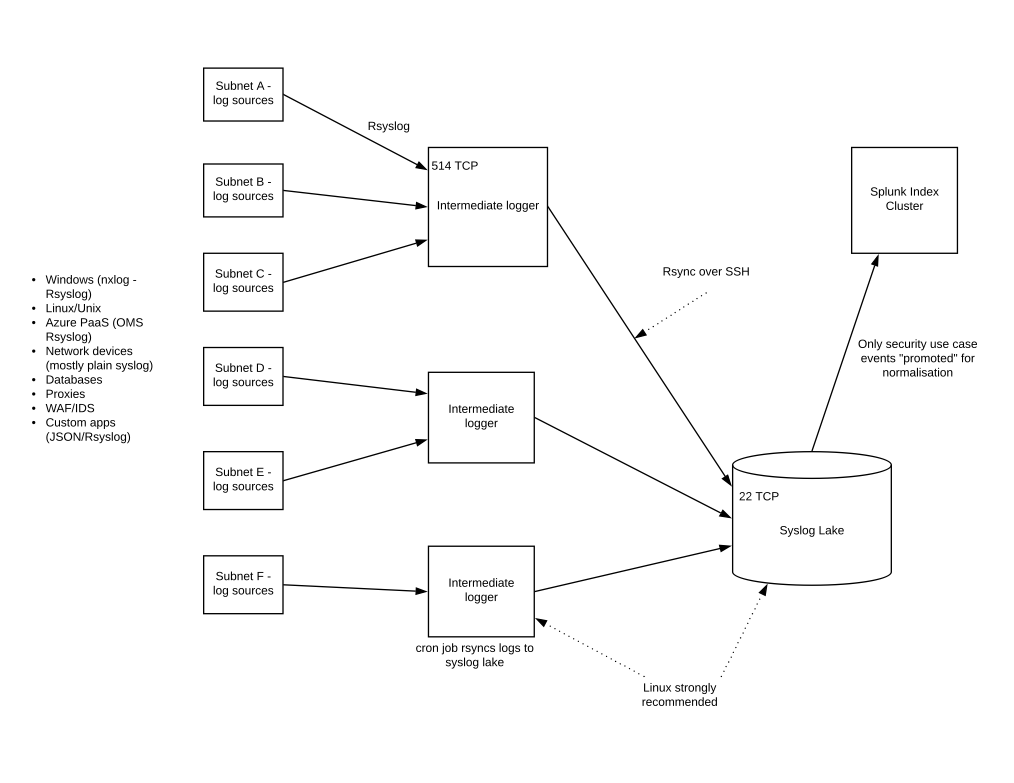

 Whenever you are trying to build something complex with lots of moving parts, architecture is used to reduce the problem down to a manageable size, and help to build good practices in risk management. The end goal is protective monitoring of an infrastructure that is built with requirements for meeting both risk and compliance challenges.
Whenever you are trying to build something complex with lots of moving parts, architecture is used to reduce the problem down to a manageable size, and help to build good practices in risk management. The end goal is protective monitoring of an infrastructure that is built with requirements for meeting both risk and compliance challenges.

