
It’s clear from social media and first hand reports, that the awareness of what VA (Vulnerability Assessment) scanners are really doing in testing scenarios is quite low. So I setup up a test box with Ubuntu 18 and exposed some services which are well known to the hacker community and also still popular in production business use cases: Secure Shell (SSH) and an Apache web service.
This post isn’t an attack on VA products at all. It’s aimed at setting a more healthy expectation, and I will cover a test scenario with a packet sniffer (Wireshark), Nessus Professional, and OpenVAS, that illustrates the point.
I became aware 20 years ago, from validating VA scanner output, that a lot of what VA scanners barf out is alarmist (red flags, CRITICAL [fix NOW!]) and also based purely on guesswork – when the scanner “sees” a service, it grabs a service banner (e.g. “OpenSSH 7.6p1 Ubuntu 4ubuntu0.3”), looks in its database for public disclosed vulnerability with that version, and flags vulnerability if there are any associated CVEs. Contrary to popular belief, there is no actual interaction in the way of further investigating or validating vulnerability. All vulnerability reporting is based on the service banner. So if i change my banner to “hi OpenVAS”, nothing will be reported. And in security, we like to advise hiding product names and versions – this helps with drive-by style automated attacks, in a much more effective way than for example, changing default service ports.
This article then demonstrates the VA scanner behaviour described above and covers developments over the past 20 years (did things improve?) with the two most commonly found scanners: Nessus and OpenVAS, which even if are not used directly, are used indirectly (vendors in this space do not recreate the wheel, they take existing IP – all legal I’m sure – and create their own UI for it). It was fairly well-known that Nessus was the basis of most commercial VAs in the 00s, and it seems unlikely that scenario has changed a great deal.
Test Setup
So if I look at my test box setup I see from port scan results (nmap):
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0)
25/tcp open smtp Postfix smtpd
80/tcp open http Apache httpd 2.4.29 ((Ubuntu))
139/tcp open netbios-ssn Samba smbd 3.X - 4.X (workgroup: WORKGROUP)
445/tcp open netbios-ssn Samba smbd 3.X - 4.X (workgroup: WORKGROUP)
3000/tcp open http Apache httpd 2.4.29 ((Ubuntu))
5000/tcp open http Docker Registry (API: 2.0)
8000/tcp open http Apache httpd 2.4.29
So…naughty, naughty. Apache is not so old but still I’d expect to see some CVEs flagged, and I can say the same for the SSH service. Samba is there too in a default format. Samba is Linux’s implementation of MS Windows SMB (Server Message Block) and is full of holes. The Postfix mail service is also quite old, and there’s a Docker API exposed! All this would get an attacker quite excited, and indeed there’s plenty of automated attack scenarios which would work here.
There was also an EOL Phpmyadmin and EOL jQuery wrapped up in the web service.
Developments in Two Decades
So there has been some changes. For want of a better word, there’s now more honesty. In the case of OpenVAS, for vulnerability that involves grabbing a banner and assuming vulnerability based on this, there is a Quality of Detection (QoD) rating, which is set as default at around 70%. This is a kind of probability rating for a finding not being a false positive. Interestingly those findings that involve a banner grab are way down there under 50, and most are no longer flagged as “critical”.
Nessus, for its banner-grabbed vulnerabilities, is more explicit and it is report will state “Note that Nessus has not tested for this issue but has instead relied only on the application’s self-reported version number.”
Even 7 years ago, there would be lots of issues reported for an outdated Apache or SSH service, many of which would be flagged wrongly as CRITICAL, but not necessarily exploitable, and the existance of the vulnerability was based only on a text banner. So these more recent VA versions are an improvement, but its clear the awareness out there of these issues is still quite low. The problem is now – we do want to see if services are downlevel, so please $VENDOR, don’t hide them (more on this later).
First Scan – Banners On Display
So using Wireshark, sniffing HTTP on port 80 (plain text) we have the following…
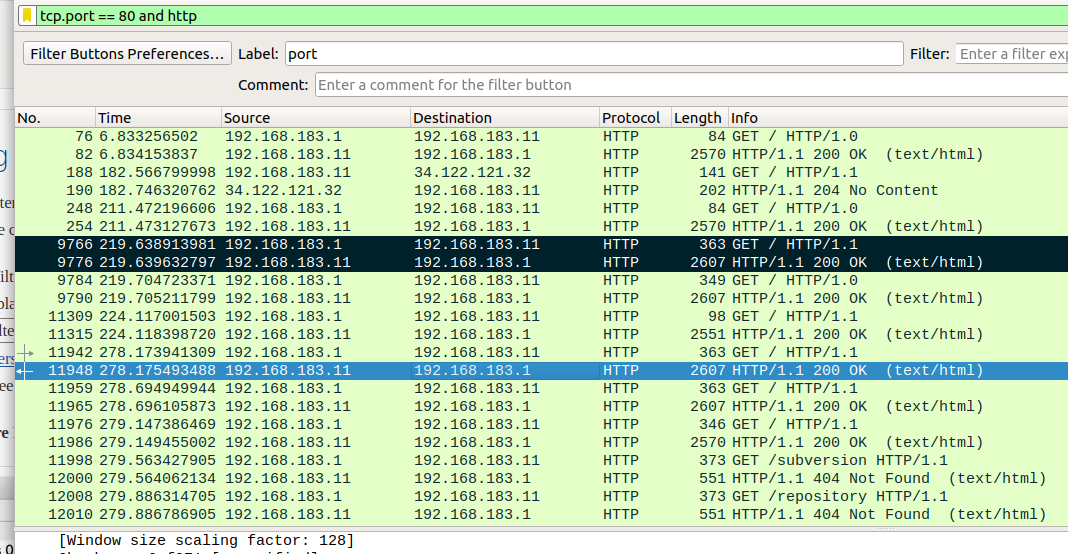
The packets highlighted in black are the only two of any interest, wherein OpenVAS has used the HTTP GET method to request for “/”, and receives a response where the header shows the product (Apache) and version (2.4.29).
Note the Wireshark filter used (tcp.port == 80 and http). Other than the initial exchange where a banner was grabbed, there was no further interaction. This was the same for Nessus.
What was reported? Well, for OpenVAS, a handful of potential CVEs were reported but I had to lower the QoD to see them! Which is interesting. If anything this is moving the bar too far in the opposite direction. I mean as an owner of this system, I do want to know if i am running old warez!
For Nessus, 6 Apache CVEs were reported with either critical or “high” severity. Overall, I had a similar experience with that of OpenVAS except to even see the Apache issues reported I had to beg the scanner with the following scan configuration setup:
- Settings –> Assessment –> Override normal accuracy and show potential false alarms
- Settings –> Assessment –> perform thorough tests
- Settings –> Advanced –> enable safe checks on (and i also tried the “off” option)
- Settings –> Advanced –> plugins –> web servers –> enabled. This is the Apache vulnerability section
For the SSH service, OpenVAS reported 3 medium issues which is roughly what i was expecting. Nessus did not report any at all! Answers on a postcard for that one.
Banners Concealed
What was interesting was that the Secure Shell service doesn’t present an option to hide the banner any more, and on investigation, the majority-held community-version of this story is that the banner is needed in some cases.
Apache however did present a banner obfuscation option. For Ubuntu 18 and Apache 2.4.29, this involved:
apt install libapache2-mod-security2a2enmod security2- edit /etc/apache2/conf-available/security.conf
- ServerTokens set to “Prod”
systemctl restart apache2
This setup results in the following banner for Apache: Apache httpd – so no version number.
The outcome? As expected, all mention of Apache has now ended. Neither OpenVAS or Nessus reported anything to do with Apache of any note.
What DID The Scanners Find?
Just to summarise the findings when the banners were fully on display…it wasn’t a blank slate. There were some findings. Here are the highlights – for OpenVAS:
- All Critical issues detected were related to PHPMyAdmin, plus one related to jQuery being EOL, but not stating any particular vulnerability. These version numbers are remotely queriable and this is the basis on which these issues were reported.
- The SSH and Apache issues.
- Other lower criticality issues were around certificate ciphers.
- Some CVSS 6, medium issues with Samba – again these are banner-grabbed guesswork findings.
Nessus didn’t report anything outside of what OpenVAS flagged. OpenVAS reported significantly more issues.
It should be said that both scanners did a lot of querying for HTTP application layer issues that could be seen in the packet sniffer output. For example, queries were made for Python/Django settings.py (database password), and other HTTP gotchas.
Unauthenticated Versus Credentialed Testing
With VA Scanners, the picture hasn’t really changed in 20 years. If anything the picture is worse now because the balance with banner-grabbing guesswork has swung too far the other way, and we have to plead with the scanners to tell us about downlevel software versions. This is presumably an effort to reduce the number of false positives, but its not an advisable strategy. It’s perfectly ok to let us know we are running old wares and if we want, we should be able to see the CVEs associated with our listening services, even if many of them are false positives (and I can say from 20 years of network penetration testing, there will be plenty).
With this type of unauthenticated VA scanning though, the real problem has always been false negatives (to the extent that an open Docker API wasn’t flagged as a problem by either scanner), but none of the other commercial tools out there (I have tried a few in recent years) will be in a better position, because there is hard-limit that can be achieved non-locally with no adminstrative authentication credentials.
Both Nessus and OpenVAS allow use of credentialled based testing but its clear this aspect was never a part of the core design. Nessus has expanded its portfolio of credentialed tests but in the time allocated I could not get it to work with SSH public key authentication. In any case, a CIS benchmark approach will always be not-so-great, for reasons outside the scope of this article. We also have to be careful about where authentication credentials are stored. In the case of SSH keys, this means storing a private key, and with some vendors the key will be stored in their cloud somewhere out there.
Conclusion
This post focusses on one major aspect of VA scanning that is grabbing banners and reporting on vulnerability based on the findings from the banner. This is better than nothing but its futility is hopefully illustrated here, and this approach is core to most of what VA scanners do for us.
The market priority has always been towards unauthenticated scanning. Little focus was ever given to credentialed scanning. This has to change because the unauthenticated approach is like trying to diagnose a problem with your car without ever lifting the bonnet/hood, and moreover we could be moving into an era where accreditation bodies mandate credentialed scanning.

