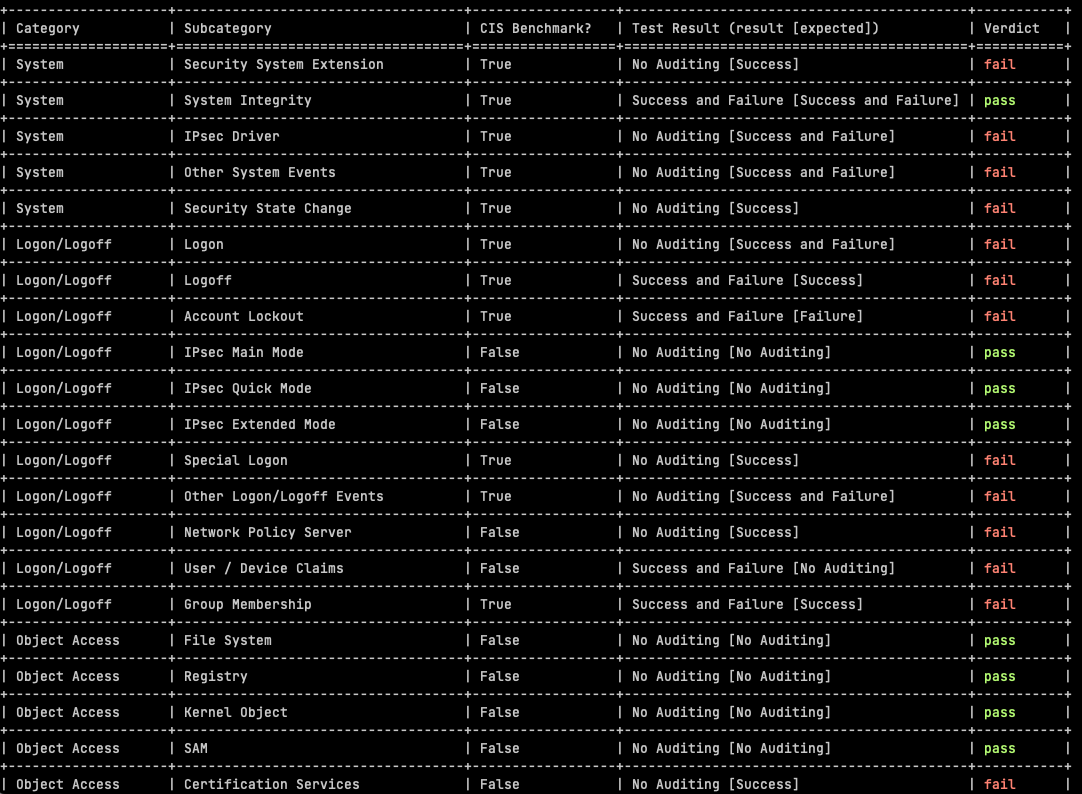
In the previous post on the subject of Windows SIEM, we covered the CIS benchmarks for Windows Auditing Policy in a spreadsheet, which was provided freely (really, actually free).
This week we introduce a python open source tool we have developed, to automate the CIS Benchmark testing.
The automated assessment results from AuditpolCIS, as it’s based on CIS Benchmarks, helps in the support of meeting audit requirements for a number of programs, not least PCI-DSS:
Audit account logon events: Helps in monitoring and logging all attempts to authenticate user credentials (PCI-DSS Requirement 10.2.4).
Audit object access: Monitors access to objects like files, folders, and registry keys that store cardholder data (PCI-DSS Requirement 10.2.1).
Audit privilege use: Logs any event where a user exercises a user right or privilege (PCI-DSS Requirement 10.2.2).
Local log files sizes and retention policies are useful in assessing compliance with e.g. 5.3.4 and 10.5.1 requirements (PCI-DSS 4). There should be a block of text after the audit policy results.
Usage / Setup
First you will to set up a Python Virtual Environment. Ensure that you have Python installed on your system (Python 3.10 was used in development). If not, download and install Python from the official website: https://www.python.org/downloads/
Open a Command Prompt or terminal window and navigate to the folder where you extracted the AuditpolCIS project.
Run the following command to create a new virtual environment:
python -m venv venv
Activate the virtual environment by running:
For Windows:
venv\Scripts\activate
For macOS/Linux:
source venv/bin/activate
Install the required Python packages from the requirements.txt file by running:
pip install -r requirements.txt
You will need a .env file in your project root. The contents relate to the target you wish to test:
HOSTNAME='<Windows box IP address or host name>' USERNAME='<Windows user account name>' PASSWORD='<account password>'
Make sure to assign the right ownership and permission on .env. Usually the permissions will be 600.
Once the virtualenv is enabled, you can run the code:
The CIS benchmarks are based on Windows 2019 Server but they apply to other target varients on a Windows theme. I know none of you will have EOL Windows versions. <Sarcasm engaged>I mean in 22 years of consulting, i’ve never seen any out-of-support warez in critical business usage</Sarcasm engaged>.
Powershell is not required on the target but use of Powershell is also not a crime. Yes, that was a security person who said that.
Sustainability / Use of Regex
I had to use some fairly snazzy regex to pull out Categories (category_pattern = r'^(\w+.*?)(\r)?$') and Subcategories (subcategory_pattern = r'^( {2})([^ ]+.*?)(?=\s{3,})(.*\S)') from the auditpol command output. I did look at more sustainable ways of achieving the same goal, although admittedly i didn’t spend much time doing that. One thing has been clear for a long time with Windows – don’t go looking for registry keys because that can be very painful. Not only is documentation for a key location somewhat thin and erroneous, the key loation also often changes across Windows versions. ChatGPT‘s lack of knowledge of Windows reg keys bears testimony to the previous comments.
So there are two sources of Subcategory names – there is cis-benchmarks.yaml and there is the output of the auditpol /get /category:* command. If there are entries in the YAML file which are not in the auditpol output, they are flagged in the script output, and the same is true vice versa. So if you make spelling mistakes in the excel sheet or YAML file, it will be flagged. It can also happen that auditpol output subcategories do not reflect the CIS Benchmarks subcategories, perhaps with different Windows versions as targets. Any of these categories will be flagged by the script and listed below the pass/fail results.
If you want to change the verdicts or [Sub]Category names, you are of course free to do so. You can edit the cis-benchmarks.yaml file, or edit the included spreadsheet, followed by running the included genyaml.py.
I know use of AutoAddPolicy with Paramiko in Python is not good form, but also assume that as an admin in the position of someone who performs daily tasks using administrative rights, that you know your hosts. Sometimes security people do get in the way of progress, when there’s low risk issues afoot. Use of RejectPolicy instead of auto-add would be one such case.
Tests Rationalisation
Some of the tests included are not a CIS Benchmark (out of 59 tests, 32 are CIS Benchmarks, whereas 27 are not). It’s not clear why the subcategories were omitted by CIS but anyway – in these cases we have made an assessment based on logging events volume for this subcategory, versus the security value of the subcategory. Most of these are just noise, and in many cases, very high volume noise, so we have advised “No Auditing”.
Customising Test Criteria
The testing template is formed of the YAML file cis-benchmarks.yaml. If you prefer to make changes to the testing template with Excel, the sheet is CIS-Audit-Reqs-Windows2019Server.xlsxin the code root. You can then use the python script genyaml.py to generate a new YAML file (you will need to use the right virtualenv, see above for usage instructions).
It’s clear from social media and first hand reports, that the awareness of what VA (Vulnerability Assessment) scanners are really doing in testing scenarios is quite low. So I setup up a test box with Ubuntu 18 and exposed some services which are well known to the hacker community and also still popular in production business use cases: Secure Shell (SSH) and an Apache web service.
This post isn’t an attack on VA products at all. It’s aimed at setting a more healthy expectation, and I will cover a test scenario with a packet sniffer (Wireshark), Nessus Professional, and OpenVAS, that illustrates the point.
I became aware 20 years ago, from validating VA scanner output, that a lot of what VA scanners barf out is alarmist (red flags, CRITICAL [fix NOW!]) and also based purely on guesswork – when the scanner “sees” a service, it grabs a service banner (e.g. “OpenSSH 7.6p1 Ubuntu 4ubuntu0.3”), looks in its database for public disclosed vulnerability with that version, and flags vulnerability if there are any associated CVEs. Contrary to popular belief, there is no actual interaction in the way of further investigating or validating vulnerability. All vulnerability reporting is based on the service banner. So if i change my banner to “hi OpenVAS”, nothing will be reported. And in security, we like to advise hiding product names and versions – this helps with drive-by style automated attacks, in a much more effective way than for example, changing default service ports.
This article then demonstrates the VA scanner behaviour described above and covers developments over the past 20 years (did things improve?) with the two most commonly found scanners: Nessus and OpenVAS, which even if are not used directly, are used indirectly (vendors in this space do not recreate the wheel, they take existing IP – all legal I’m sure – and create their own UI for it). It was fairly well-known that Nessus was the basis of most commercial VAs in the 00s, and it seems unlikely that scenario has changed a great deal.
Test Setup
So if I look at my test box setup I see from port scan results (nmap):
PORT STATE SERVICE VERSION 22/tcp open ssh OpenSSH 7.6p1 Ubuntu 4ubuntu0.3 (Ubuntu Linux; protocol 2.0) 25/tcp open smtp Postfix smtpd 80/tcp open http Apache httpd 2.4.29 ((Ubuntu)) 139/tcp open netbios-ssn Samba smbd 3.X - 4.X (workgroup: WORKGROUP) 445/tcp open netbios-ssn Samba smbd 3.X - 4.X (workgroup: WORKGROUP) 3000/tcp open http Apache httpd 2.4.29 ((Ubuntu)) 5000/tcp open http Docker Registry (API: 2.0) 8000/tcp open http Apache httpd 2.4.29
So…naughty, naughty. Apache is not so old but still I’d expect to see some CVEs flagged, and I can say the same for the SSH service. Samba is there too in a default format. Samba is Linux’s implementation of MS Windows SMB (Server Message Block) and is full of holes. The Postfix mail service is also quite old, and there’s a Docker API exposed! All this would get an attacker quite excited, and indeed there’s plenty of automated attack scenarios which would work here.
There was also an EOLPhpmyadmin and EOL jQuery wrapped up in the web service.
Developments in Two Decades
So there has been some changes. For want of a better word, there’s now more honesty. In the case of OpenVAS, for vulnerability that involves grabbing a banner and assuming vulnerability based on this, there is a Quality of Detection (QoD) rating, which is set as default at around 70%. This is a kind of probability rating for a finding not being a false positive. Interestingly those findings that involve a banner grab are way down there under 50, and most are no longer flagged as “critical”.
Nessus, for its banner-grabbed vulnerabilities, is more explicit and it is report will state “Note that Nessus has not tested for this issue but has instead relied only on the application’s self-reported version number.”
Even 7 years ago, there would be lots of issues reported for an outdated Apache or SSH service, many of which would be flagged wrongly as CRITICAL, but not necessarily exploitable, and the existance of the vulnerability was based only on a text banner. So these more recent VA versions are an improvement, but its clear the awareness out there of these issues is still quite low. The problem is now – we do want to see if services are downlevel, so please $VENDOR, don’t hide them (more on this later).
First Scan – Banners On Display
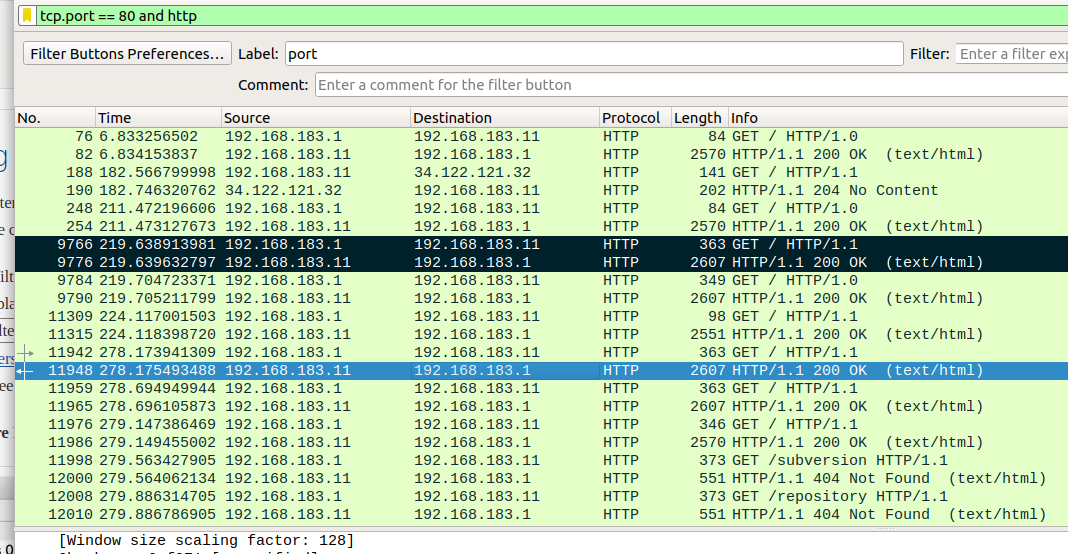
So using Wireshark, sniffing HTTP on port 80 (plain text) we have the following…
Wireshark window showing the OpenVAS interaction with the text box target
The packets highlighted in black are the only two of any interest, wherein OpenVAS has used the HTTP GET method to request for “/”, and receives a response where the header shows the product (Apache) and version (2.4.29).
Note the Wireshark filter used (tcp.port == 80 and http). Other than the initial exchange where a banner was grabbed, there was no further interaction. This was the same for Nessus.
What was reported? Well, for OpenVAS, a handful of potential CVEs were reported but I had to lower the QoD to see them! Which is interesting. If anything this is moving the bar too far in the opposite direction. I mean as an owner of this system, I do want to know if i am running old warez!
For Nessus, 6 Apache CVEs were reported with either critical or “high” severity. Overall, I had a similar experience with that of OpenVAS except to even see the Apache issues reported I had to beg the scanner with the following scan configuration setup:
Settings –> Assessment –> Override normal accuracy and show potential false alarms
Settings –> Assessment –> perform thorough tests
Settings –> Advanced –> enable safe checks on (and i also tried the “off” option)
Settings –> Advanced –> plugins –> web servers –> enabled. This is the Apache vulnerability section
For the SSH service, OpenVAS reported 3 medium issues which is roughly what i was expecting. Nessus did not report any at all! Answers on a postcard for that one.
Banners Concealed
What was interesting was that the Secure Shell service doesn’t present an option to hide the banner any more, and on investigation, the majority-held community-version of this story is that the banner is needed in some cases.
Apache however did present a banner obfuscation option. For Ubuntu 18 and Apache 2.4.29, this involved:
apt install libapache2-mod-security2
a2enmod security2
edit /etc/apache2/conf-available/security.conf
ServerTokens set to “Prod”
systemctl restart apache2
This setup results in the following banner for Apache: Apache httpd – so no version number.
The outcome? As expected, all mention of Apache has now ended. Neither OpenVAS or Nessus reported anything to do with Apache of any note.
What DID The Scanners Find?
Just to summarise the findings when the banners were fully on display…it wasn’t a blank slate. There were some findings. Here are the highlights – for OpenVAS:
All Critical issues detected were related to PHPMyAdmin, plus one related to jQuery being EOL, but not stating any particular vulnerability. These version numbers are remotely queriable and this is the basis on which these issues were reported.
The SSH and Apache issues.
Other lower criticality issues were around certificate ciphers.
Some CVSS 6, medium issues with Samba – again these are banner-grabbed guesswork findings.
Nessus didn’t report anything outside of what OpenVAS flagged. OpenVAS reported significantly more issues.
It should be said that both scanners did a lot of querying for HTTP application layer issues that could be seen in the packet sniffer output. For example, queries were made for Python/Django settings.py (database password), and other HTTP gotchas.
Unauthenticated Versus Credentialed Testing
With VA Scanners, the picture hasn’t really changed in 20 years. If anything the picture is worse now because the balance with banner-grabbing guesswork has swung too far the other way, and we have to plead with the scanners to tell us about downlevel software versions. This is presumably an effort to reduce the number of false positives, but its not an advisable strategy. It’s perfectly ok to let us know we are running old wares and if we want, we should be able to see the CVEs associated with our listening services, even if many of them are false positives (and I can say from 20 years of network penetration testing, there will be plenty).
With this type of unauthenticated VA scanning though, the real problem has always been false negatives (to the extent that an open Docker API wasn’t flagged as a problem by either scanner), but none of the other commercial tools out there (I have tried a few in recent years) will be in a better position, because there is hard-limit that can be achieved non-locally with no adminstrative authentication credentials.
Both Nessus and OpenVAS allow use of credentialled based testing but its clear this aspect was never a part of the core design. Nessus has expanded its portfolio of credentialed tests but in the time allocated I could not get it to work with SSH public key authentication. In any case, a CIS benchmark approach will always be not-so-great, for reasons outside the scope of this article. We also have to be careful about where authentication credentials are stored. In the case of SSH keys, this means storing a private key, and with some vendors the key will be stored in their cloud somewhere out there.
Conclusion
This post focusses on one major aspect of VA scanning that is grabbing banners and reporting on vulnerability based on the findings from the banner. This is better than nothing but its futility is hopefully illustrated here, and this approach is core to most of what VA scanners do for us.
The market priority has always been towards unauthenticated scanning. Little focus was ever given to credentialed scanning. This has to change because the unauthenticated approach is like trying to diagnose a problem with your car without ever lifting the bonnet/hood, and moreover we could be moving into an era where accreditation bodies mandate credentialed scanning.
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Logging
Notice “Logging” is used here, not “SIEM”. With use of “SIEM”, there is often a mental leap, or stumble, towards a commercial solution. But there doesn’t necessarily need to be a commercial solution. This post invites the reader to take a step back from the precipice of engaging with vendors, and check first if that journey is one you want to make.
Unfortunately, in 2020, it is still the case that many fintechs are doing one of two things:
Procuring a commercial solution without thinking about what is going to be logged, or thinking about the actual business goals that a logging solution is intended to achieve.
Just going with the Cloud Service Provider’s (CSP) SaaS offering – e.g. Stackdriver (now called “Operations”) for Google Cloud, or Security Center for Azure.
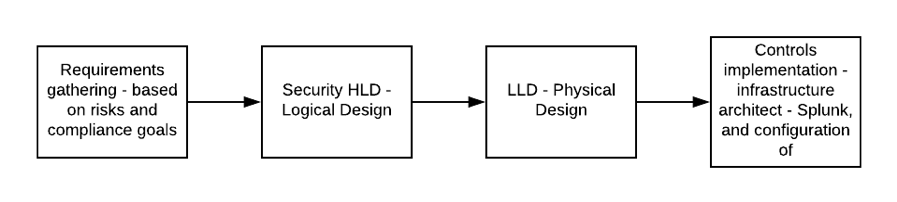
Design Process
The process HLD takes into risks from threat modelling (and maybe other sources), and another input from compliance requirements (maybe security standards and legal requirements), and uses the requirements from the HLD to drive the LLD. The LLD will call out the use cases and volume requirements that satisfy the HLD requirements – but importantly, it does not cover the technological solution. That comes later.
The diagram above calls out Splunk but of course it doesn’t have to be Splunk.
Security Operations
The end goal of the design process is heavily weighted towards a security operations or protective monitoring capability. Alerts will be specified which will then be configured into the technological solution (if it supports this). Run-books are developed based on on-going continuous improvement – this “tuning” is based on adjusting to false positives mainly, and adding further alerts, or modifying existing alerts.
The decision making on how to respond to alerts requires intimate knowledge of networks and applications, trust relationships, data flows, and the business criticality of information assets. This is not a role for fresh graduates. Risk assessment drives the response to an alert, and the decision on whether or not to engage an incident response process.
General IT monitoring can form the first level response, and then Security Operations consumes events from this first level that are related to potential security incidents.
Two main points relating this SecOps function:
Outsourcing doesn’t typically work when it comes to the 2nd level. Outsourcing of the first level is more likely to be cost effective. Dr Anton Chuvakin’s post on what can, and cannot be outsourced in security is the most well-rounded and realistic that i’ve seen. Generally anything that requires in-house knowledge and intimacy of how events relate to business risks – this cannot be outsourced at all effectively.
The maturity of SecOps doesn’t happen overnight. Expect it to take more than 12 months for a larger fintech with a complex cloud footprint.
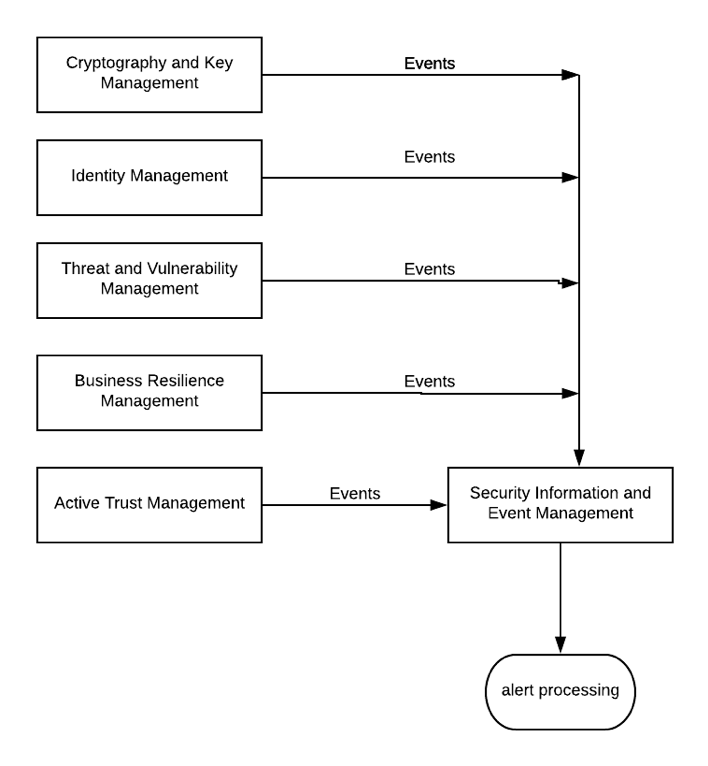
The logging capability is the bedrock of SecOps, and how it relates to other security capabilities can be simplified as in the diagram below. The boxes on the left are self-explanatory with the possible exception of Active Trust Management – this is heavily network-oriented and at the engineering end of the rainbow, its about firewalls, reverse and forward proxies mainly:
Custom Use Cases
For the vast majority of cases, custom use cases will need to be formulated. This involves building a picture of “normal”, so as to enable alerting on abnormal. So taking the networking example: what are my data flows? Take my most critical applications – what are source and destination IP addresses, and what is the port on the server-side of the client-server relationship? So then a possible custom use case could be: raise an alert when a connection is aimed at the server from anywhere other than the client(s).
Generic use cases are no-brainers. Examples are brute force attempts and technology or user behaviour-specific use cases. Some good examples are here. Custom use cases requires an understanding of how applications, networks, and operating systems are knitted together. But both custom and generic use cases require a log source to be called out. For network events, this will be a firewall as the best candidate. It generally makes very little sense to deploy network IDS nodes in cloud.
So for each application, generate a table of custom use cases, and identify a log source for each. Generic use cases are those configured auto-tragically in Splunk Enterprise Security for example. But even Splunk cannot magically give you custom use cases, or even ensure that all devices are included in the coverage for generic use cases. No – humans still have a monopoly over custom use cases and well, really, most of SIEM configuration. AI and Cyberdyne Systems won’t be able to get near custom use cases in our lifetimes, or ever, other than the fantasy world of vendor Powerpoint slides.
Don’t forget to test custom use case alerting. So for network events, spin up a VM in a centrally trusted area, like a management Vnet/VPC for example. Port scan from there to see if alerts are triggered. Netcat can be very useful here too, for spoofing source addresses for example.
Correlation
Correlation was the phrase used by vendors in the heady days of the 00s. The premise was something like this: event A, event B, and event C. Taken in isolation (topical), each seem innocuous. But bake them together and you have a clear indicator that skullduggery is afoot.
I suggest you park correlation in the early stage of a logging capability deployment. Maybe consider it for down the road, once a decent level of maturity has been reached in SecOps, and consider also that any attempt to try and get too clever can result in your SIEM frying circuit boards. The aim initially should be to reduce complexity as much as possible, and nothing is better at adding complexity than correlation. Really – basic alerting on generic and custom use cases gives you most of the coverage you need for now, and in any case, you can’t expect to get anywhere near an ideal state with logging.
SaaS
Operating system logs are important in many cases. When you decide to SaaS a solution, note that you lose control over operating system events. You cannot turn off events that you’re not interested in (e.g. Windows Object auditing events which have had a few too many pizzas). This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
Note – its also, in most cases, not such a great idea to use a SaaS based SIEM. Why? Because this function has connectivity with everything. It has trust relationships with dev/test, pre-prod, and production. You really want full control over this platform (i.e. be able to login with admin credentials and take control of the OS), especially as it hosts lots of information that would be very interesting for attackers, and is potentially the main target for attackers, because of the trust relationships I mentioned before.
So with SaaS, its probably not the case that you are missing critical events. You just get flooded. The same applies to 3rd party applications, but for custom, in-house developed applications, you still have control of course of the application layer.
Custom, In-house Developed Applications
You have your debugging stream and you have your application stream. You can assign critical levels to events in your code (these are the classic syslog severity levels). The application events stream is critical. From an application security perspective, many events are not immediately intuitively of interest, but by using knowledge of how hackers work in practice, security can offer some surprises here, pleasant or otherwise.
If you’re a developer, you can ease the strain on your infosec colleagues by using consistent JSON logging keys across the board. For example, don’t start with ‘userid’ and then flip to ‘user_id’ later, because it makes the configuration of alerting more of a challenge than it needs to be. To some extent, this is unavoidable, because different vendors use different keys, but every bit helps. Note also that if search patterns for alerting have to cater for multiple different keys in JSON documents, the load on the SIEM will be unnecessarily high.
It goes without saying also: think about where your application and debug logs are being transmitted and stored. These are a source of extremely valuable intelligence for an attacker.
The Technology
The technological side of the logging capability isn’t the biggest side. The technology is there to fulfil a logging requirement, it is not in itself the logging capability. There are also people and processes around logging, but its worth talking about the technology.
What’s more common than many would think – organisation acquires a COTS SIEM tool but the security engineers hate it. Its slow and doesn’t do much of any use. So they find their own way of aggregating network-centralised events with a syslog bucket of some description. Performance is very often the reason why engineers will be grep’ing over syslog text files.
Whereas the aforementioned sounds ineffective, sadly its more effective than botched SIEM deployments with poorly designed tech. It also ticks the “network centralised logging” box for auditors.
The open-source tools solution can work for lots of organisations, but what you don’t get so easily is the real-time alerting. The main cost will be storage. No license fees. Just take a step back, and think what it is you really want to achieve in logging (see the design process above). The features of the open source logging solution can be something like this:
Rsyslog is TCP and covers authentication of hosts. Rsyslog is a popular protocol because it enables TCP layer transmission from most log source types (one exception is some Cisco network devices and firewalls), and also encryption of data in transit, which is strongly recommended in a wide open, “flat” network architecture where eavesdropping is a prevalent risk.
Even Windows can “speak” rsyslog with the aid of a local agent such as nxlog.
There are plenty of Host-based Intrusion Detection System (HIDS) agents for Linux and Windows – OSSEC, Suricata, etc.
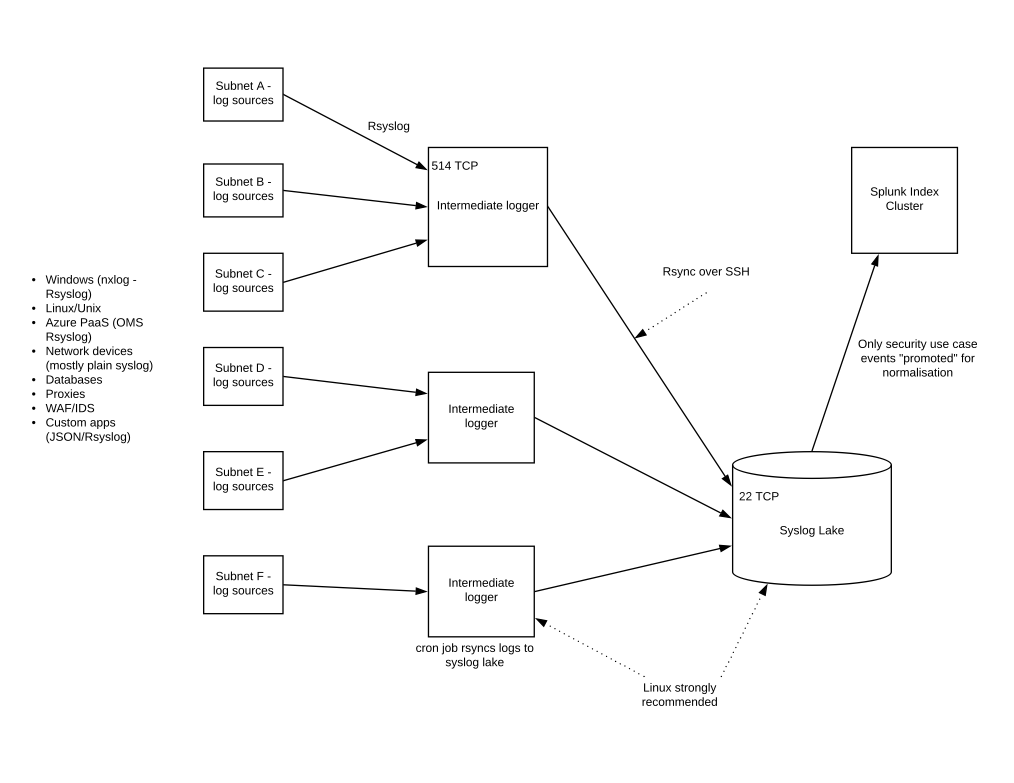
Intermediate network logging Rsyslog servers can aggregate logs for network zones/subnets. There are the equivalent of Splunk forwarders or Alienvault Sensors. A cron job runs an rsync over Secure Shell (SSH), which uploads the batches of events data periodically to a Syslog Lake, for want of a better phrase.
The folder structure on the Syslog server can reflect dates – years, months, days – and distinct files are named to indicate the log source or intermediate server.
Splunk sales people have a dart board with my picture on it. To be fair, the official Splunk line is that they want to help their customers save events indexing money because it benefits them in the longer term. And they’re right, this does work for Splunk and their customers. But many of the resellers are either lacking the skills to help, or they are just interested in a quick and dirty install. “Live for today, don’t worry about tomorrow”.
Splunk really is a Lamborghini, and the few times when i’ve been involved in bidding beauty parades for SIEM, Splunk often comes out cheaper believe it or not. Splunk was made for logging and was engineered as such. Some of the other SIEM engines are poorly coded and connect to a MySQL database for example, whereas Splunk has its own database effectively. The difference in performance is extraordinary. A Splunk search involving a complex regex with busy indexers and search heads takes a fraction of the time to complete, compared with a similar scenario from other tools on the same hardware.
Three main ways to reduce events indexing costs with Splunk:
Root out useless events. Windows is the main culprit here, in particular Auditing of Objects. Do you need, for example, all that performance monitoring data? Debug events? Firewall AND NIDS events? Denied AND accepted packets from firewalls?
You can be highly selective about which events are forwarded to the Splunk indexer. One conceptual model just to illustrate the point is given below:
Threat Hunting
Threat Hunting is kind of the sexy offering for the world of defence. Offence has had more than its fair share of glamour offerings over the years. Now its defence’s turn. Or is it? I mean i get it. It’s a good thing to put on your profile, and in some cases there are dramatic lines such as “be the hunter or the hunted”.
However, a rational view of “hunting” is that it requires LOTS of resources and LOTS of skill – two commodities that are very scarce. Threat hunting in most cases is the worst kind of resources sink hole. If you take vulnerability management (TVM) and the kind of basic detection discussed thus far in this article, you have a defence capability that in most cases fits the risk management needs of the organisation. So then there’s two questions to ask:
How much does threat hunting offer on top of a suitably configured logging and TVM capability? Not much in the best of cases. Especially with credentialed scanning with TVM – there is very little of your attack surface that you cannot cover.
How much does threat hunting offer in isolation (i.e. threat hunting with no TVM or logging)? This is the worst case scenario that will end up getting us all fired in security. Don’t do it!!! Just don’t. You will be wide open to attack. This is similar to a TVM program that consists only of one-week penetration tests every 6 months.
Threat Intelligence (TI)
Ok so here’s a funny story. At a trading house client here in London around 2016: they were paying a large yellow vendor lots of fazools every month for “threat intelligence”. I couldn’t help but notice a similarity in the output displayed in the portal as compared with what i had seen from the client’s Alienvault. There is a good reason for this: it WAS Alienvault. The feeds were coming from switches and firewalls inside the client network, and clearly $VENDOR was using Alienvault also. So they were paying heaps to see a duplication of the data they already had in their own Alienvault.
The aforementioned is an extremely bad case of course. The worst of the worst. But can you expect more value from other threat intelligence feeds? Well…remember what i was saying about the value of an effective TVM and detection program? Ok I’ll summarise the two main problems with TI:
You can really achieve LOTS in defence with a good credentialed TVM program plus even a half-decent logging program. I speak as someone who has lots of experience in unrestricted penetration testing – believe me you are well covered with a good TVM and detection SecOps function. You don’t need to be looking at threats apart from a few caveats…see later.
TI from commercial feeds isn’t about your network. Its about the whole planet. Its like picking up a newspaper to find out what’s happening in the world, and seeing on the front cover that a butterfly in China has flapped its wings recently.
Where TI can be useful – macro developments and sector-specific developments. For example, a new approach to Phishing, or a new class of vulnerability with software that you host, or if you’re in the public sector and your friendly national spy agency has picked up on hostile intentions towards you. But i don’t want to know that a new malware payload has been doing the rounds. In the time taken to read the briefing, 2000 new payloads have been released to the wild.
Summary
Start out with a design process that takes input feeds from compliance and risk (perhaps threat modelling), use the resulting requirements to drive the LLD, which may or may not result in a decision to procure tech that meets the requirements of the LLD.
An effective logging capability can only be designed with intimate knowledge of the estate – databases, crown jewels, data flows – for each application. Without such knowledge, it isn’t possible to build even a barely useful logging capability. Call out your generic and custom use cases in your LLD, independent of technology.
Get your basic alerting first, correlation can come later, if ever.
Outsourcing is a waste of resources for second level SecOps.
With SaaS, your SIEM itself is dangerously exposed, and you have no control over what is logged from SaaS log sources.
You are not mandated to get a COTS. Think about what it is that you want to achieve. It could be that open source tools across the board work for you.
Splunk really is the Lamborghini of SIEMs and the “expensive” tag is unjustified. If you carefully design custom and generic use cases, and remove everything else from indexing, you suddenly don’t have such an expensive logger. You can also aggregate everything in a Syslog pool before it hits Splunk indexers, and be more selective about what gets forwarded.
I speak as someone with lots of experience in unrestricted penetration testing: Threat Hunting and Threat Intelligence aren’t worth the effort in most cases.
Netdelta is a tool for monitoring networks and flagging alerts upon changes in advertised services. Now – I like Python and especially Django, and around 2014 or so i was asked to setup a facility for monitoring for changes in that organisation’s perimeter. After some considerable digging, i found nada, as in nothing, apart from a few half-baked student projects. So i went off and coded Netdelta, and the world has never been the same since.
I guess when i started with Netdelta i didn’t see it as a solution that would be widely popular because i was under the impression you could just do some basic shell scripting with nmap, and ndiff is specifically designed for delta flagging. However what became apparent at an early stage was that timeouts are a problem. A delta will be flagged when a host or service times out – and this happens a lot, even on a gigabit LAN, and it happens even more in public clouds. I built some analytics into Netdelta that looks back over the scan history and data and makes a call on the likelihood of a false positive (red, amber green).
Most organisations i worked with would benefit from this. One classic example i can think of – a trading house that had been on an aggressive M&A spree, maybe it was Black Friday or…? Anyway – they fired some network engineers and hired some new and cheaper ones, exacerbating what was already a poorly managed perimeter scenario. CISO wanted to know what was going off with these Internet facing subnets – enter Netdelta. Unauthorised changes are a problem! I am directly aware of no fewer than 6 incidents that occurred as a result of exposed SSH, SMB (Wannacry), and more recently RDP, and indirectly aware of many more.
Anyway without further waffle, here’s how you get Netdelta up and running. Warning – there are a few moving parts, but if someone wants it in Docker, let me know.
I always go with Ubuntu. The differences between Linux distros are like the differences between mueslis. My build was on 18.04 but its highly likely 19 variants will be just fine.
Make the logs dir, e.g. /logs, and you will need to modify /nd/netdelta_logger.py to point to this location. Note the celery monitor logs go to /var/log/celery/celery-monitor.log …which of course you can change.
Strip world permissions from all netdelta and apache root dirs:
You can use whatever supported database you like. MySQL is assumed here.
The Python framework mysqlclient was used with earlier versions of Django and MySQL. but with Python 3 and later Django versions, the word on the street is PyMySQL is the way to go. With this though, it took some trickery to get the Django project up and running; in the form of init.py for the project (<netdelta root>/netdelta/.init.py) and adding a few lines …
import pymysql
pymysql.install_as_MySQLdb()
While in virtualenv, and under your netdelta root, add a superuser for the DF
Patch libnmap
Two main mods to the libnmap in usage with Netdelta were necessary. First, with later versions of Celery (>3.1), there was a security issue with “deamonic processes are not allowed to have children”, for which an alternative fork of libnmap fixed the problem. Then we needed to return to Netdelta the process id of the running nmap port scanner process.
cd /opt
git clone https://github.com/pyoner/python-libnmap.git
cp ./python-libnmap/libnmap/process.py <virtualenv root>/lib/python3.x/site-packages/libnmap/
then patch libnmap to allow Netdelta to kill scanning processes
<netdelta_root>/scripts/fix-libnmap.bash
Change the environment variables to match your install and use the virtualenv name as a parameter
Database Setup
Create a database called netdetla and use whichever encoding snd collation you like.
CREATE DATABASE netdelta CHARACTER SET utf8 COLLATE utf8_general_ci;
Then from <netdelta root> with virtualenv engaged:
I am assuming all you good security pros don’t want to use the development server? Well as you’re only dealing with port scan data then….your call. I’m assuming Apache as a production web server.
You will need to give Apache a stub web root and enable the wsgi module. For the latter i added this to apache2.conf – this gives you some control over the exact version of Python loaded.
I have to say, when I read the title of the article, the cynic in me once again prevailed. And indeed there will be some cynicism and sarcasm in this article, so if that offends the reader, i would like to suggest other sources of information: those which do not accurately reflect the state of the information security industry. Unfortunately the truth is often accompanied by at least cynicism. Indeed, if I meet an IT professional who isn’t cynical and sarcastic, I do find it hard to trust them.
Near the end of the article there will be a quiz with a scammed prize offering, just to take the edge of the punishment of the endless “negativity” and abject non-MBA’edness.
“While organizations have been hot to virtualize their machine operations, that zeal hasn’t been transferred to their adoption of good security practices”. Well you see they’re two different things. Using VMs reduces power and physical space requirements. Note the word “physical” here and being physical, the benefits are easier to understand.
Physical implies something which takes physical form – a matter energy field. Decision makers are familiar with such energy fields. There are other examples in their lives such as tables, chairs, other people, walls, cars. Then there is information in electronic form – that’s a similar thing (also an energy field) but the hunter/gatherer in some of us doesn’t see it that way, and still as of 2013, the concept eludes many IT decision makers who have fought their way up through the ranks as a result of excellent performance in their IT careers (no – it’s not just because they have a MBA, or know the right people).
There is a concept at board level of insuring a building (another matter energy field) against damages from natural causes. But even when 80% of information assets are in electronic form, there is still a disconnect from the information. Come on chaps, we’ve been doing this for 20 years now!
Josh Corman recently tweeted “We depend on software just as much as steel and concrete, its just that software is infinitely more attack-able!”. Mr Corman felt the need to make this statement. Ok, like most other wise men in security, it was intended to boost his Klout score, but one does not achieve that by tweeting stuff that everybody already knows. I would trust someone like Mr Corman to know where the gaps are in the mental portfolios of IT decision makers.
Ok, so moving on…”Nearly half (42 percent) of the 346 administrators participating in the security vendor BeyondTrust‘s survey said they don’t use any security tools regularly as part of operating their virtual systems…”
What tools? You mean anti-virus and firewalls, or the latest heuristic HIDS box of shite? Call me business-friendly but I don’t want to see endless tools on end points, regardless of their function. So if they’re not using tools, is it not at this point good journalism to comment on what tools exactly? Personally I want to see a local firewall and the obligatory and increasingly less beneficial anti-virus (and i do not care as to where, who, whenceforth, or which one…preferably the one where the word “heuristic” is not used in the marketing drivel on the box). Now if you’re talking system hardening and utilizing built-in logging capability – great, that’s a different story, and worthy of a cuddly toy as a prize.
“Insecure practices when creating new virtual images is a systemic problem” – it is, but how many security problems can you really eradicate at build-time and be sure that the change won’t break an application or introduce some other problem. When practical IT-oriented security folk actually try to do this with skilled and experienced ops and devs, they realise that less than 50% of their policies can be implemented safely in a corporate build image. Other security changes need to be assessed on a per-application basis.
Forget VMs and clouds for a moment – 90%+ of firms are not rolling out effectively hardened build images for anyplatform. The information security world is still some way off with practices in the other VM field (Vulnerability Management).
“If an administrator clones a machine or rolls back a snapshot,”… “the security risks that those machines represent are bubbled up to the administrator, and they can make decisions as to whether they should be powered on, off or left in state.”
Ok, so “the security risks that those machines represent are bubbled up to the administrator”!!?? [Double-take] Really? Ok, this whole security thing really can be automated then? In that case, every platform should be installed as a VM managed under VMware vCenter with the BeyondTrust plugin. A tab that can show us our risks? There has to be a distinction between vulnerability and risk here, because they are two quite different things. No but seriously, I would want to know how those vulnerabilities are detected because to date the information security industry still doesn’t have an accurate way to do this for some platforms.
Another quote: “It’s pretty clear that virtualization has ripped up operational practices and that security lags woefully behind the operational practice of managing the virtual infrastructure,”. I would edit that and just the two words “security” and “lags”. What with visualized stuff being a subset of the full spectrum of play things and all.
“Making matters worse is that traditional security tools don’t work very well in virtual environments”. In this case i would leave remaining five words. A Kenwood Food Mixer goes to the person who can guess which ones those are. See? Who said security isn’t fun?
“System operators believe that somehow virtualization provides their environments with security not found in the world of physical machines”. Now we’re going Twilight Zone. We’ve been discussing the inter-cluster sized gap between the physical world and electronic information in this article, and now we have this? Segmentation fault, core dumped.
Anyway – virtualization does increase security in some cases. It depends how the VM has been configured and what type of networking config is used, but if we’re talking virtualised servers that advertise services to port scanners, and / or SMB shares with their hosts, then clearly the virtualised aspect is suddenly very real. VM guests used in a NAT’ing setup is a decent way to hide information on a laptop/mobile device or anything that hooks into an untrusted network (read: “corporate private network”).
The vendor who was being interviewed finished up with “Every product sounds the same,” …”They all make you secure. And none of them deliver.” Probably if i was a vendor I might not say that.
Sorry, I just find discussions of security with “radical new infrastructure” to be something of a waste of bandwidth. We have some very fundamental, ground level problems in information security that are actually not so hard to understand or even solve, at least until it comes to self-reflection and the thought of looking for a new line of work.
All of these “VM” and “cloud” and “BYOD” discussions would suddenly disappear with the introduction of integrity in our little world because with that, the bigger picture of skills, accreditation, and therefore trust would be solved (note the lack of a CISSP/CEH dig there).
I covered the problems and solutions in detail in Security De-engineering, but you know what? The solution (chapter 11) is no big secret. It comes from the gift of intuition with which many humans are endowed. Anyway – someone had to say it, now its in black and white.
Yes, ladies and gentlemen, hardening is hard. If its not hard, then there are two possibilities. One is that the maturity of information security in the organization is at such a level that security happens both effectively and transparently – its fully integrated into the fabric of BAU processes and many of said processes are fully automated with accurate results. The second (far more likely given the reality of security in 2013) is that the hardening is not well implemented.
For the purpose of this diatribe, let us first define “hardening” so that we can all be reading from the same hymn sheet. When I’m talking about hardening here, the theme is one of first assessing vulnerability, then addressing the business risk presented by the vulnerability. This can apply to applications, or operating systems, or any aspect of risk assessment on corporate infrastructure.
In assessing vulnerability, if you’re following a check list, hardening is not hard – in fact a parrot can repeat pearls of wisdom from a check list. But the result of merely following a check list will be either wide open critical hosts or over-spending on security – usually the former. For sure, critical production systems will be impacted, and I don’t mean in a positive way.
You see, like most things in security, some thinking is involved. It does suit the agenda of many in this field to pretend that security analysis can be reduced down to parrot-fashion recital of a check list. Unfortunately though, some neural activity is required, at least if gaining the trust of our customers (C-levels, other business units, home users, etc) is important to us.
The actual contents of the check list should be the easy part, although unfortunately as of 2013, we all seem to be using different versions of the check list, and some versions are appallingly lacking. The worst offenders here deliver with a quality that is inversely proportional to the prices they charge – and these are usually external auditors from big 4 consultancies, all of whom have very decent check lists, but who also fail to ensure that Consultants use said check list. There are plenty of cases where the auditor knocks up their own garage’y style shell script for testing. In one case i witnessed not so long ago, the script for testing RedHat Enterprise Linux consisted of 6 tests (!) and one of the tests showed a misunderstanding of the purpose of the /etc/ftpusers file.
But the focus here is not on the methods deployed by auditors, its more general than that. Vulnerability testing in general is not a small subject. I have posted previously on the subject of “manual” network penetration testing. In summary: there will be a need for some businesses to show auditors that their perimeter has been assessed by a “trusted third party”, but in terms of pure value, very few businesses should be paying for the standard two week delivery with a four person team. For businesses to see any real value in a network penetration test, their security has to be at a certain level of maturity. Most businesses are nowhere near that level.
Then there is the subject of automated, unauthenticated “scanning” techniques which I have also written about extensively, both in an earlier post and in Chapter Five of Security De-engineering. In summary, the methodology used in unauthenticated vulnerability scanning results in inaccuracy, large numbers of false positives, wasted resources, and annoyed operations and development teams. This is not a problem with any particular tool, although some of them are especially bad. It is a limitation of the concept of unauthenticated testing, which amounts to little more than pure guesswork in vulnerability assessment.
How about the growing numbers of “vulnerability management” products out there (which do not “manage” vulnerability, they make an attempt at assessing vulnerability)? Well, most of them are either purely an expensive graphical interface to [insert free/open source scanner name], or if the tool was designed to make a serious attempt at accurate vulnerability assessment (more of them do not), then the tests will be lacking or over-done, inaccurate, and / or doing the scanning in an insecure way (e.g. the application is run over a public URL, with the result that all of your configuration data, including admin passwords, are held by an untrusted third party).
In one case, a very expensive VM product literally does nothing other than port scan. It is configured with hundreds of “test” patterns for different types of target (MS Windows, *nix, etc) but if you’re familiar with your OS configurations,you will look at the tool output and be immediately suspicious. I ran the tool against a Linux and Windows test target and “packet sniffed” the scanning engine’s probe attempts. In summary, the tool does nothing. It just produces a long list of configuration items (so effectively a kind of Security Standard for the target) without actually testing for the existence of vulnerability.
So the overall principle: the company [hopefully] has a security standard for each major operating system and database on their network and each item in the standard needs to be tested for all, or some of the information asset hosts in the organization, depending on the overall strategy and network architecture. As of the time of writing, there will need to be some manual / scripted augmentation of automatic vulnerability assessment processes.
So once armed with a list of vulnerabilities, what does one do with it? The vulnerability assessment is the first step. What has to happen after that? Can Security just toss the report over to ops and hope for the best? Yes, they can, but this wouldn’t make them very popular and also there needs to be some input from security regarding the actual risk to the business. Taking the typical function of operations teams (I commented on the functions and relationships between security and operations in an earlier post), if there is no input from security, then every risk mitigation that meets any kind of an impact will be blocked.
There are some security service providers/consultancies who offer a testing AND a subsequent hardening service. They want to offer both detection AND a solution, and this is very innovative and noble of them. However, how many security vulnerabilities can be addressed blindly without impacting critical production processes? Rhetorical question: can applications be broken by applying security fixes? If I remove the setuid bit from a root owned X Window related binary, it probably has no effect on business processes. Right? What if operations teams can no longer authenticate via their usual graphical interface? This is at least a little bit disruptive.
In practice, as it turns out, if you look at a Security Standard for a core technology, lets take Oracle 11g as an example: how many of the numerous elements of a Security Standard can we say can be implemented without fear of breaking applications, limiting access for users or administrators, or generally just making trouble-shooting of critical applications a lot less efficient? The answer is: not many. Dependencies and other problems can come from surprising sources.
Who in the organization knows about dependencies and the complexities of production systems? Usually that would be IT / Network Operations. And how about application – related dependencies? That would be application architects, or just generally we’ll say “dev teams” as they’re so affectionately referred to these days. So the point: even if security does have admin access to IT resources (rare), is the risk mitigation/hardening a job purely for security? Of course the answer is a resounding no, and the same goes for IT Operations.
So, operations and applications architects bring knowledge of the complexities of apps and infrastructure to the table. Security brings knowledge of the network architecture (data flows, firewall configurations, network device configurations), the risk of each vulnerability (how hard is to exploit and what is the impact?), and the importance to the business of information assets/applications. Armed with the aforementioned knowledge, informed and sensible decisions on what to do with the risk (accept, mitigate, work around, or transfer) can be made by the organization, not by security, or operations.
The early days of deciding what to do with the risk will be slow and difficult and there might even be some feisty exchanges, but eventually, addressing the risk becomes a mature, documented process that almost melts into the background hum of the machinery of a business.
I would like to start by issuing a warning about the content in this article. I will be taking cynicism to the next level, so the baby-eyed, and “positive” among us should avert their gaze after this first paragraph. For those in tune with their higher consciousness, I will summarise: Can we blame the C-levels for our problems? Answer: no. Ok, pass on through now. More positive vibes may be found in the department of delusion down the hall.
The word “salt” was for the first time ever inserted into the hall of fame of Information Security buzzwords after the Linkedin hack infamy, and then Yahoo came along and spoiled the ridicule-fest by showing to the world that they could do even better than Linkedin by not actually using any password hashing at all.
There is a tendency among the masses to latch onto little islands of intellectual property in the security world. Just as we see with “cloud”, the “salt” element of the Linkedin affair was given plenty of focus, because as a result of the incident, many security professionals had learned something new – a rare occurrence in the usual agenda of tick-in-box-marking that most analysts are mandated to follow.
With Linkedin, little coverage was given to the tedious old nebulous “compromise” element, or “how were the passwords compromised?”. No – the “salt” part was much more exciting to hose into blogs and twitter – but with hundreds of analysts talking about the value of “salting”, the value of this pearl of wisdom was falling exponentially with time – there was a limited amount of time in which to become famous. If you were tardy in showing to the world that you understood what “salting” means, your tweet wouldn’t be favourite’d or re-tweeted, and the analyst would have to step back off the stage and go back to their usual humdrum existence of entering ticks in boxes, telling devs to use two-factor authentication as a matter of “best practices”, “run a vulnerability scanner against it”, and such ticks related matters.
Infosec was down and flailing around helplessly, then came the Linkedin case. The inevitable fall-out from the “salting” incident (I don’t call it the Linkedin incident any more) was a kick of sand in the face of the already writhing information security industry. Although I don’t know of any specific cases, based on twelve happy years of marriage with infosec, i’m sure they’re as abundant as the stars and occurring as I write this. I am sure that nine times out of ten, whenever devs need to store a password, they are told by CISSP-toting self-righteous analysts (and blindly backed up by their managers) that it is “best practice” and “mandatory” to use salting with passwords – regardless of all the other factors that go into making up the full picture of risk, the operational costs, and other needless over-heads. There will be times when salting is a good idea. Other times not. There cannot be a zero-value proposition here – but blanket, parrot-fashion advisories are exactly that.
The subject matter of the previous four paragraphs serves as a recent illustrator of our plight in security. My book covers a much larger piece of the circus-o-sphere and its certainly too much to even to try to summarise here, but we are epic-failing on a daily basis. One of the subjects I cover in Security De-engineering is the role of C-Level executives in security, and I ask the question “can we blame the C-levels” for the broken state of infosec?
Let’s take a trip down memory lane. The heady days of the late 90s were owned by technical wizards, sometimes known as Hackers. They had green hair and piercings. If a CEO ran some variant of a Windows OS on her laptop, she was greeted with a stream of expletives. Ok, “best practices” was nowhere to be seen in the response, and it is a much more offensive swear-phrase than any swear word I can think of, but the point is that the Hacker’s reposte could be better.
Hackers have little or no business acumen. They have the tech talent that the complexities of information security afford, but back when they worked in infosec in the late 90s, they were poorly managed. Artists need an agent to represent them, and there were no agents.
Hackers could theoretically be locked in a room with a cat-flap for food and drink, no email, and no phone. The only person they should be allowed to communicate with is their immediate security line manager. They could be used as a vault of intellectual capital, or a swiss army knife in the organisation. Problem was – the right kind of management was always lacking. Organisations need an interface between themselves and the Hackers. No such interface ever existed unfortunately.
The upper levels of management gave up working with Hackers for various reasons, not just for scaring the living daylights out of their normal earthling colleagues. Then came the early noughties. Hackers were replaced by respectable analysts with suits and ties, who sounded nice, used the words “governance” and “non-repudiation” a lot, and didn’t swear at their managers regardless of ineptitude levels. The problem with the latter CASE (Checklist and Standards Evangelist) were illustrated with the “salting” debacle and Linkedin.
There is a link between information and information security (did you notice the play on words there – information was used in…”information”… and also in… “information security” – thereby implicating that there might just be a connection). The CASE successor to the realm actually managed to convince themselves (but few others in the business world) that security actually has nothing to do with information technology. It is apparently all about “management” and “processes”. So – every analyst is now a “manager”?! So who in the organisation is going to actually talk to ops and devs and solve the risk versus cost of safeguard puzzles? There are no foot soldiers, only a security department composed entirely of managers.
Another side of our woes is the security products space. Products have been lobbied by fierce marketing engines and given ten-out-of-ten ratings by objective information security publications. The products supposedly can automate areas of information risk management, and tell us things we didn’t already know about our networks. The problem is when you automate processes, you’re looking for accurate results. Right? Well, in certain areas such as vulnerability assessment, we don’t even get close to accurate results – and vulnerability assessment is one area where accuracy is sorely needed – especially if we are using automation to assess vulnerability in critical situations.
Some product classes do actually make some sense to deploy in some business cases, but the number of cases where something like SIEM (for example) actually make sense as as an investment is a small number of the whole.
Security line managers feel the pressure of compliance as the main part of their function. In-house advice is pretty much of the out-house variety in most cases, and service providers aren’t always so objective when it comes to technology acquisition. Products are purchased as a show of diligence for clueless auditors and a short cut to a tick-in-a-box.
So the current security landscape is one of a lack of appropriate skills, especially at security line-management level, which in turn leads to market support for whatever bone-headed product idea can be dreamed up next. The problems come in two boxes then – skills and products.
Is it the case that security analysts and line managers are all of the belief that everything is fine in their corner? The slew of incidents, outgoing connections to strange addresses in eastern Europe, and the loss of ownership of workstation subnets – it’s not through any fault of information security professionals? I have heard some use the excuse “we can never keep out bad guys all the time” – which actually is true, but there is little real confidence in the delivery of this message. Even with the most confidence – projecting among us, there is an inward sense of disharmony with things. We all know, just from intuition, that security is about IT (not just business) and that the value we offer to businesses is extremely limited in most cases.
CEOs and other silver-heads read non-IT publications, and often-times incidents will be reported, even in publications such as the Financial Times. Many of them are genuinely concerned about their information assets, and they will ask for updates from someone like a CISO. It is unlikely the case, as some suggest, they don’t care about information security and it is also unlikely, as is often claimed, that security budgets are rejected minus any consideration.
CEOs will make decisions on security spending based on available information. Have they ever been in a position where they can trust us with our line reporting? Back in the 90s they were sworn at with business-averse rhetoric. Later they were bombarded with IT-averse rhetoric, green pie charts from expensive vulnerability management suites, delivered with a perceptible lack of confidence in analyst skills and available tools.
So can we blame CEOs? Of course not, and our prerogative now should be re-engineering of skills, with a better system of “graduation” through the “ranks” in security, and an associated single body of accreditation (Chapter 11 of Security De-engineering covers this in more detail). With better skills, the products market would also follow suit and change radically. All of this would enable CISOs to report on security postures with confidence, which in turn enables trust at the next level up the ladder.
The idea that CEOs are responsible for all our problems is one of the sacred holy cows of the security industry (along with some others that I will be covering). Ladies and gentlemen: security analysts, managers, self-proclaimed “Evangelists”, “Subject Matter Experts”, and other ego-packing gurus of our time are responsible for the problems.
Not sure how resistant is your password to real world hacker password enumeration vectors? There’s an app for that.
The folks over at Literatecode have developed an IPhone app called isPasswordOK to help the average person select a strong password.
When users sign-up for online services they are often asked to give a password. They enter the password, as an example…”Password”, this doesn’t pass the test on the blog sign-up form? However “P4ssw0rd” passes the test (there’s a Javascript “password strength” indicator script that assesses password strength allegedly), but those meters do not take into account real world enumeration/ccracking techniques. Generally the user is told they have a “Good” or “fair” password as long as their password passes the format test (e.g. One upper case, one lower case, one punctuation mark) . Clearly to those in the know, P4ssw0rd is a bad password, but not according to most online registration form strength indicators.
Passwords authentication poses a nightmare for users and security departments. They can’t be too complex because then they get written down somewhere where others can see them (in one case the employee wrote a password on the ceiling board over their desk). Then…obviously they can’t be too simple. But passwords are all we have in many cases, so let’s do our best to choose a good one – and this is not as simple as many folk believe it to be.
This app is a nice innovation, long overdue, and sorely needed, as demonstrated by the myriad of password compromises globally.

 This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.