I’ve spent 25 years in information security. Long enough to see SIEM rise from the old audit requirements of “aggregated, network based logging”, with the birth of the “correlation” buzzword, and with its fall seen the rise of the “normalisaton” buzzword. I’ve built SOCs, tuned them, fought alert noise, and tried to control the spiralling cost that comes with doing security badly at scale.
And through all of that, one principle has never changed.
Know your environment. Know your security strategy. Understand your threat model. Build a picture of normal. Alert on what is truly abnormal—and truly risky.
The Sacred Cows of the SOC
If you follow the above-described approach, something interesting happens. A number of “must-haves” in modern SOC conversations start to look… negotiable:
SOAR is not always mandatory
Threat hunting is cool
More analysts does not equal better outcomes
Expensive threat intelligence feeds are mandatory
These are not heretical views—they’re just uncomfortable ones. Because they challenge a model where complexity and cost are often mistaken for maturity.
In reality, a well-understood environment with sharply defined risk tolerance will outperform a bloated SOC every time.
Enter AI: The New Buzzword Cycle
Now we have a new layer: AI, and if you read the current wave of content, you’ll notice a pattern. The most confident “AI success stories” tend to avoid talking about SIEM at all!
Instead, we get familiar phrases:
“Enriching data feeds”
“Augmenting analysts”
Let’s pause on one of those.
“Enrichment” of Data
“Enrichment” has quietly joined the long list of SIEM buzzwords. But what does it actually mean? Better data? According to whom? Data quality is not universal. It is entirely dependent on your environment, your systems, and your risks. An event that is critical in one organisation is meaningless in another.
You can train an AI model to process data. But can you teach it what matters in a specific, messy, evolving environment? That’s not just a data problem. That’s a context problem.
The Analyst Productivity Argument
Another popular claim:
“AI won’t replace analysts, but it will make them more productive.”
It sounds reasonable. It’s also mostly unproven in the SIEM context. Take “noise reduction”—a classic SOC problem. Who defines noise?
That decision requires:
Knowledge of the environment
Understanding of business risk
Familiarity with attacker behaviour
That’s not magic. But it does require experience and judgement. Can an AI learn this? Possibly, in constrained scenarios. Can it generalise this across real-world environments without introducing blind spots? That’s much harder to believe.
The Missing Layer: Technical Depth
What’s consistently absent from “AI transformed my SOC” narratives is technical depth.
Where are the discussions about?:
Operating systems
Network behaviour
Application logic
Even in fully SaaS environments, you are still dealing with operating systems, identity layers, protocols, and execution paths.
Can AI Fix a Broken SOC?
AI can easily flog a dead horse that is a cost-sinkhole SOC (plenty of those around on all continents – it needs a collective noun), but can it get a SOC to rise phoenix-like from the ashes of its dark history? That is as close to a ‘no’ as you’re ever going to get without it actually being a ‘no’.
I remain open minded, but i want to see technically grounded discussions in order to change that position. The SIEM community has long conversations for the long nights of winter e.g. “do i want to use sysmon if i have a CIS benchmark compliant Audit Policy service?”. This is the level that the conversation has to be, at, without perhaps the same volume.
AI can absolutely make those SOCs more efficient at being inefficient. can it transform a fundamentally flawed SOC into an effective one? That’s very close to a “no.” Not because AI is weak—but because the problem is structural.
If you don’t understand your environment, your risk, and your attack surface, no amount of automation will fix that.
The Hard Problem: Teaching an Attack Mindset
At its core, effective detection relies on an attack mindset.
That comes from:
Understanding how systems really behave
Knowing how they break
Seeing how attackers chain small weaknesses into real impact
We’ve seen early attempts to automate parts of this—especially in areas like network path analysis and automated penetration testing.
But anyone who has participated in real-world red teaming or unrestricted penetration testing knows the truth: This is not a linear process. It involves intuition, creativity, and adapting to incomplete information. Teaching that to an AI agent is not impossible—but it is a very hard problem.
Final Thought
I’m not anti-AI. Far from it. But I am sceptical of narratives that skip over the hard parts.
Can AI replace the fundamentals?:
Understanding your environment
Defining risk properly
Thinking like an attacker
Until AI can operate meaningfully at that level, it remains a tool, of sorts, hopefullly not a very expensive tool.
In the previous post on the subject of Windows SIEM, we covered the CIS benchmarks for Windows Auditing Policy in a spreadsheet, which was provided freely (really, actually free).
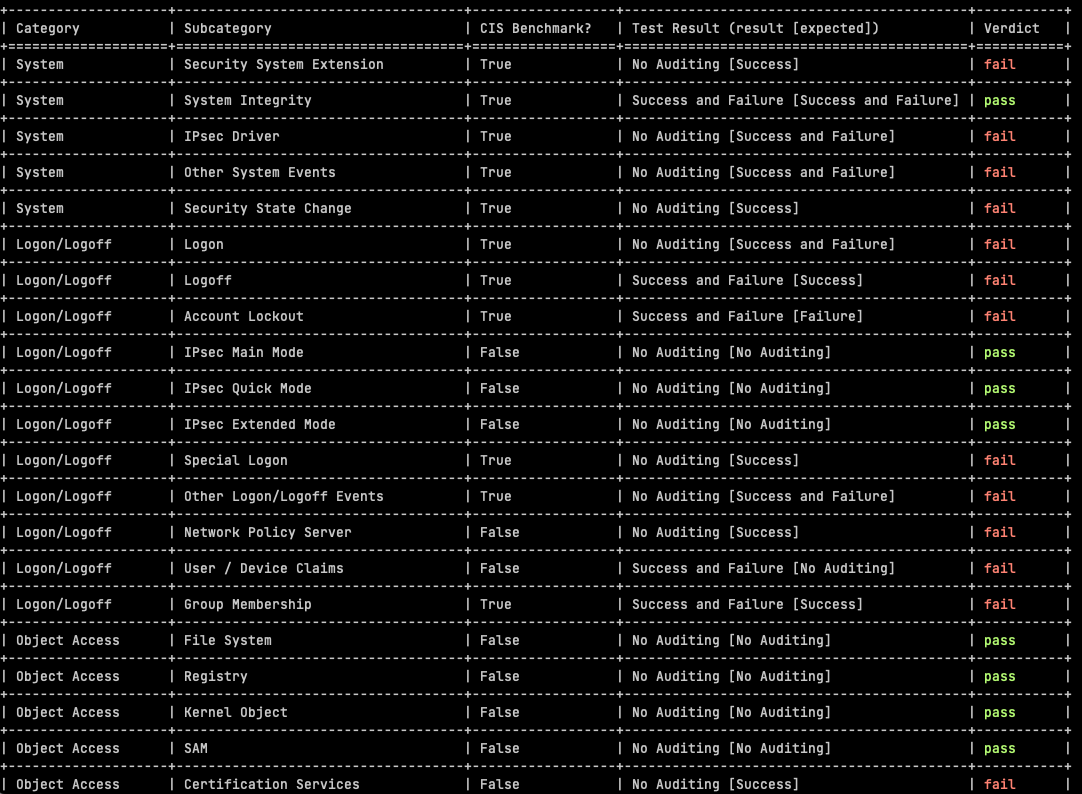
This week we introduce a python open source tool we have developed, to automate the CIS Benchmark testing.
The automated assessment results from AuditpolCIS, as it’s based on CIS Benchmarks, helps in the support of meeting audit requirements for a number of programs, not least PCI-DSS:
Audit account logon events: Helps in monitoring and logging all attempts to authenticate user credentials (PCI-DSS Requirement 10.2.4).
Audit object access: Monitors access to objects like files, folders, and registry keys that store cardholder data (PCI-DSS Requirement 10.2.1).
Audit privilege use: Logs any event where a user exercises a user right or privilege (PCI-DSS Requirement 10.2.2).
Local log files sizes and retention policies are useful in assessing compliance with e.g. 5.3.4 and 10.5.1 requirements (PCI-DSS 4). There should be a block of text after the audit policy results.
Usage / Setup
First you will to set up a Python Virtual Environment. Ensure that you have Python installed on your system (Python 3.10 was used in development). If not, download and install Python from the official website: https://www.python.org/downloads/
Open a Command Prompt or terminal window and navigate to the folder where you extracted the AuditpolCIS project.
Run the following command to create a new virtual environment:
python -m venv venv
Activate the virtual environment by running:
For Windows:
venv\Scripts\activate
For macOS/Linux:
source venv/bin/activate
Install the required Python packages from the requirements.txt file by running:
pip install -r requirements.txt
You will need a .env file in your project root. The contents relate to the target you wish to test:
HOSTNAME='<Windows box IP address or host name>' USERNAME='<Windows user account name>' PASSWORD='<account password>'
Make sure to assign the right ownership and permission on .env. Usually the permissions will be 600.
Once the virtualenv is enabled, you can run the code:
The CIS benchmarks are based on Windows 2019 Server but they apply to other target varients on a Windows theme. I know none of you will have EOL Windows versions. <Sarcasm engaged>I mean in 22 years of consulting, i’ve never seen any out-of-support warez in critical business usage</Sarcasm engaged>.
Powershell is not required on the target but use of Powershell is also not a crime. Yes, that was a security person who said that.
Sustainability / Use of Regex
I had to use some fairly snazzy regex to pull out Categories (category_pattern = r'^(\w+.*?)(\r)?$') and Subcategories (subcategory_pattern = r'^( {2})([^ ]+.*?)(?=\s{3,})(.*\S)') from the auditpol command output. I did look at more sustainable ways of achieving the same goal, although admittedly i didn’t spend much time doing that. One thing has been clear for a long time with Windows – don’t go looking for registry keys because that can be very painful. Not only is documentation for a key location somewhat thin and erroneous, the key loation also often changes across Windows versions. ChatGPT‘s lack of knowledge of Windows reg keys bears testimony to the previous comments.
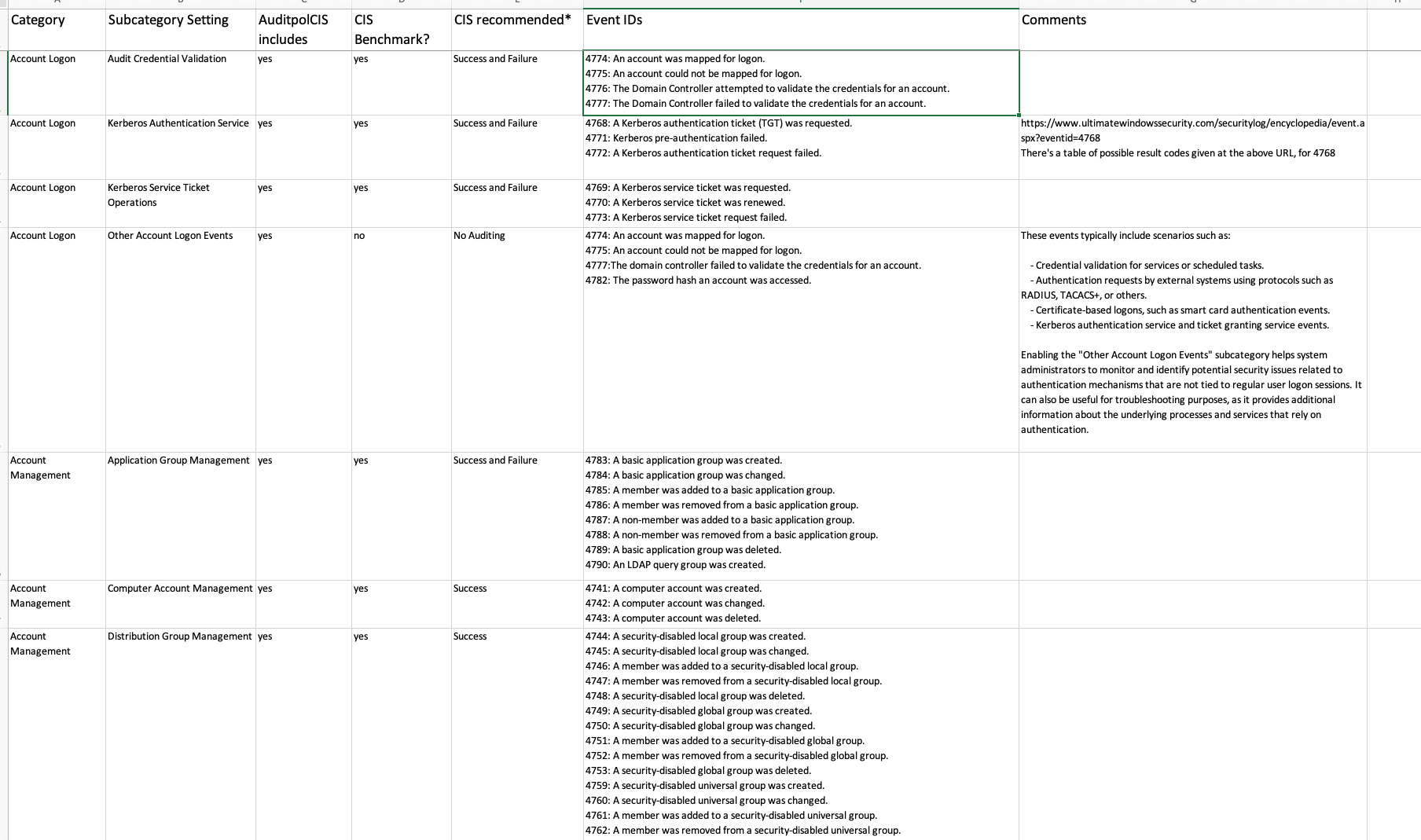
So there are two sources of Subcategory names – there is cis-benchmarks.yaml and there is the output of the auditpol /get /category:* command. If there are entries in the YAML file which are not in the auditpol output, they are flagged in the script output, and the same is true vice versa. So if you make spelling mistakes in the excel sheet or YAML file, it will be flagged. It can also happen that auditpol output subcategories do not reflect the CIS Benchmarks subcategories, perhaps with different Windows versions as targets. Any of these categories will be flagged by the script and listed below the pass/fail results.
If you want to change the verdicts or [Sub]Category names, you are of course free to do so. You can edit the cis-benchmarks.yaml file, or edit the included spreadsheet, followed by running the included genyaml.py.
I know use of AutoAddPolicy with Paramiko in Python is not good form, but also assume that as an admin in the position of someone who performs daily tasks using administrative rights, that you know your hosts. Sometimes security people do get in the way of progress, when there’s low risk issues afoot. Use of RejectPolicy instead of auto-add would be one such case.
Tests Rationalisation
Some of the tests included are not a CIS Benchmark (out of 59 tests, 32 are CIS Benchmarks, whereas 27 are not). It’s not clear why the subcategories were omitted by CIS but anyway – in these cases we have made an assessment based on logging events volume for this subcategory, versus the security value of the subcategory. Most of these are just noise, and in many cases, very high volume noise, so we have advised “No Auditing”.
Customising Test Criteria
The testing template is formed of the YAML file cis-benchmarks.yaml. If you prefer to make changes to the testing template with Excel, the sheet is CIS-Audit-Reqs-Windows2019Server.xlsxin the code root. You can then use the python script genyaml.py to generate a new YAML file (you will need to use the right virtualenv, see above for usage instructions).
In our 2021 blog post, we focused on identifying quick wins for optimizing Windows Events, and provided a free spreadsheet (really free, not even a regwall) that indicated Windows Events that could be safely ignored, some of which cost lots for SIEM engines to ingest. This post takes a broader Windows Audit Policy view, and offers another free resource – this time taking a broader look in the context of comparing your setup for Windows Audit Policy, and the venerable CIS Benchmark for Windows 2019 Server.
If there’s sufficient interest i’ll follow up with a development effort for a Python tool (also freely available, on Github) that connects to your Windows server and performs the CIS Benchmark assessment as indicated in the spreadsheet.
SIEM Nightmares
Based on many first hand observations and second hand accounts, it’s not a stretch to say that many organisations are suffering from SIEM configuration issues, for which the result is a low signal-to-noise ratio. Your SIEM is ingesting lots of events, many of which are not at all helpful, and with most vendors charging by volume, it gets expensive. At the same time, the false negative problem is all too common. Forensics investigations reveal all too often that there are no events recorded by the expensive SIEM, that even closely relate to the incident. I hope you are never in this scenario. The short-term impact is never good.
Taking SIEM as a capability, if one is to advise on how to improve things, it is rarely ever about the technology. When one asks Analysts (and based on job postings, also hiring managers) about SIEM, it’s clear the first thing that comes to mind is Splunk. ELK, Sentinel, etc. I would estimate the technology-only focus with SIEM to be the norm rather than the exception, and it comes hand-in-hand with a failure to detect privilege elevations, and lateral movements for example.
There are some advisories that we can give out that are independent of your architecture, but many questions about SIEM configuration can only be answered by you, using your knowledge of the IT landscape in your organisation. The advisories in the referenced spreadsheet cover the “noise” part of the signal-to-noise ratio. These are events that are sure to be noise to at least a 90% level of assurance, from a security perspective.
Addtional Context on the Spreadsheet
Some context around the spreadsheet: where there is a CIS Benchmark metric for a specific Audit Subcategory, the spreadsheet follows exactly the CIS recommended setting. But there are some (e.g. DS Access –> Directory Service Access) where this subcategory was not covered by CIS. In these cases, an assessment is made based on our real-experience observations of logging volumes, versus the security (not the IT diagnostic, or other value) value of Audit Subcategories. In this case of the Directory Service Access subcategory, it can be turned off from a security perspective.
There is limited information available regarding actual experiences with specific event ID volumes. In 2018, I had the opportunity to track Windows events in a Splunk architecture for a government department. During this time, I recorded the occurrences of events over a 24-hour period on a network of approximately 150 Windows servers of various versions, some of which were quite exotic. This information has been valuable in supporting decisions related to whether or not to disable auditing.
SIEM Forwarder Filtering
There is another option offered by some SIEM vendors and that is to filter events by Event ID. Overall, the more resource-friendly approach is to prevent the events being generated at source, but in many cases this may not be feasible. Splunk for example allows you to filter at forwarders (via the inputs.conf file on the Splunk forwarder. This file is usually located in the $SPLUNK_HOME/etc/system/local/ directory … more info – BTW it looks like Splunk agrees with us on the 4662 event mentioned as an example above. Yay!).
Credits and Disclaimers
Windows Events are sometimes tricky to understand, both with respect of what the developers intended with those events, and the conditions under which they are generated. Sometimes with Windows Events, we are completely in unknown territory, even if there is some Microsoft documentation that covers them. Here’s one example from Microsoft documentation to fill us with confidence – “This auditing subcategory should not have any events in it, but for some reason Success auditing will enable the generation of event 4985″.
Ultimately only you can decide what’s best for the health of your SOC/SIEM. Only you know your network and your applications. The document supplied here was only intended as a guide, and to aid decision making. It was not intended to make decisions for you.
The cybersecurity landscape often focuses on the more sensational aspects, such as high-profile hacks or fake influencers, which can overshadow the essential work done by countless professionals in the background. These unsung heroes are dedicated to ensuring the stability and security of our digital infrastructure, and their contributions should not be underestimated. Among those are tthe likes of Randy Franklin Smith (founder of Ultmate Windows Security) who has put together an “encyclopedia” of Windows Event IDs. The experiences shared there were used in-part to form a view on whether or not to reject or accept certain Windows Events.
There has been a modicum of interest in a Windows spreadsheet I shared on social media recently, that if absorbed and acted upon, can be a early no-brainer win with SIEM products that are licensed based on volume or Events Per Second (EPS).
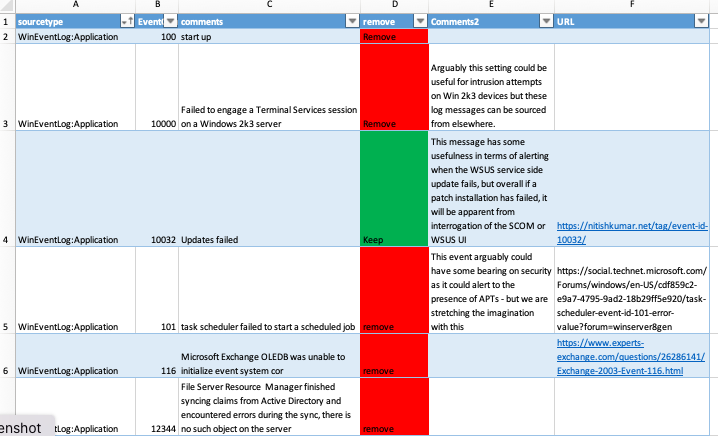
Its no big secret that Windows machines, virtual or real, are noisy. Clients I worked with – I would estimate 90%, for various reasonsdon’t act on the noise from Windows devices and it’s costing them a fortune (right or wrong, approx 50% of those prioritise other tasks).
In Splunk, one can use searches to estimate the benefit of removing noisy Windows events, and what I found was quite a broad range of results. It makes little sense to give the full breakdown because the result depends heavily on the spread and amount of Windows to other Operating Systems (OS). But there were a couple of cases where logging events volume was reduced by 70%.
Some points to note:
If the “remove” events are removed, Windows devices become very quiet. Some organisations use events as an indicator of “alive” rather than using active host monitoring. So with this logging configuration, an alternative (more sensible) host monitoring method is needed.
Removing these events is highly unlikely to ever result in a failure to detect an attack, but being 100% certain of this is impossible.
The most critical aspect of logging isn’t related to these events at all, its about your custom use cases. An example: a usual scenario is for a database listening service to accept application level connections on its listening service port (e.g. 1521 TCP is default for Oracle DB), and the source will be a web or middleware tier. So – configure an alert for when connections come from a source other than the middleware/application tier.
Very little actual analysis of Windows events and their purpose is known, or if it is known it is certainly not shared anywhere. There are some historical aspects to many of these events in that they’ve been around for more than 20 years but were never documented particualrly well, apart from here. I have added some insight but not for all events. Hence: if anyone would like any of the contents added or edited, feel free to comment below.
The context here is security. For other logging use cases, other events may need to be switched on.
The major versions of MS Windows Server that this journal applies to are: 2003, 2008, 2012. Many will apply to both 2016 and 2019.
So here are the links.. note there is no reg or pay wall. You will not be tracked and no data will be held about you. This is a completely free resource for you to collect anonymously:
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Logging
Notice “Logging” is used here, not “SIEM”. With use of “SIEM”, there is often a mental leap, or stumble, towards a commercial solution. But there doesn’t necessarily need to be a commercial solution. This post invites the reader to take a step back from the precipice of engaging with vendors, and check first if that journey is one you want to make.
Unfortunately, in 2020, it is still the case that many fintechs are doing one of two things:
Procuring a commercial solution without thinking about what is going to be logged, or thinking about the actual business goals that a logging solution is intended to achieve.
Just going with the Cloud Service Provider’s (CSP) SaaS offering – e.g. Stackdriver (now called “Operations”) for Google Cloud, or Security Center for Azure.
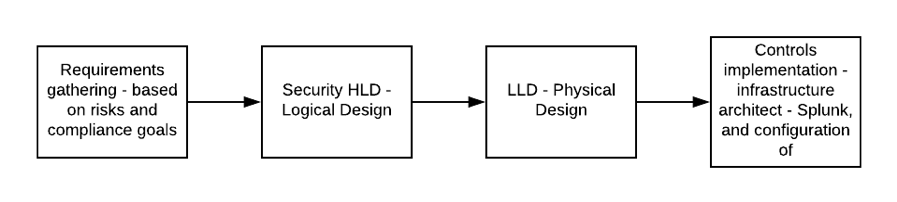
Design Process
The process HLD takes into risks from threat modelling (and maybe other sources), and another input from compliance requirements (maybe security standards and legal requirements), and uses the requirements from the HLD to drive the LLD. The LLD will call out the use cases and volume requirements that satisfy the HLD requirements – but importantly, it does not cover the technological solution. That comes later.
The diagram above calls out Splunk but of course it doesn’t have to be Splunk.
Security Operations
The end goal of the design process is heavily weighted towards a security operations or protective monitoring capability. Alerts will be specified which will then be configured into the technological solution (if it supports this). Run-books are developed based on on-going continuous improvement – this “tuning” is based on adjusting to false positives mainly, and adding further alerts, or modifying existing alerts.
The decision making on how to respond to alerts requires intimate knowledge of networks and applications, trust relationships, data flows, and the business criticality of information assets. This is not a role for fresh graduates. Risk assessment drives the response to an alert, and the decision on whether or not to engage an incident response process.
General IT monitoring can form the first level response, and then Security Operations consumes events from this first level that are related to potential security incidents.
Two main points relating this SecOps function:
Outsourcing doesn’t typically work when it comes to the 2nd level. Outsourcing of the first level is more likely to be cost effective. Dr Anton Chuvakin’s post on what can, and cannot be outsourced in security is the most well-rounded and realistic that i’ve seen. Generally anything that requires in-house knowledge and intimacy of how events relate to business risks – this cannot be outsourced at all effectively.
The maturity of SecOps doesn’t happen overnight. Expect it to take more than 12 months for a larger fintech with a complex cloud footprint.
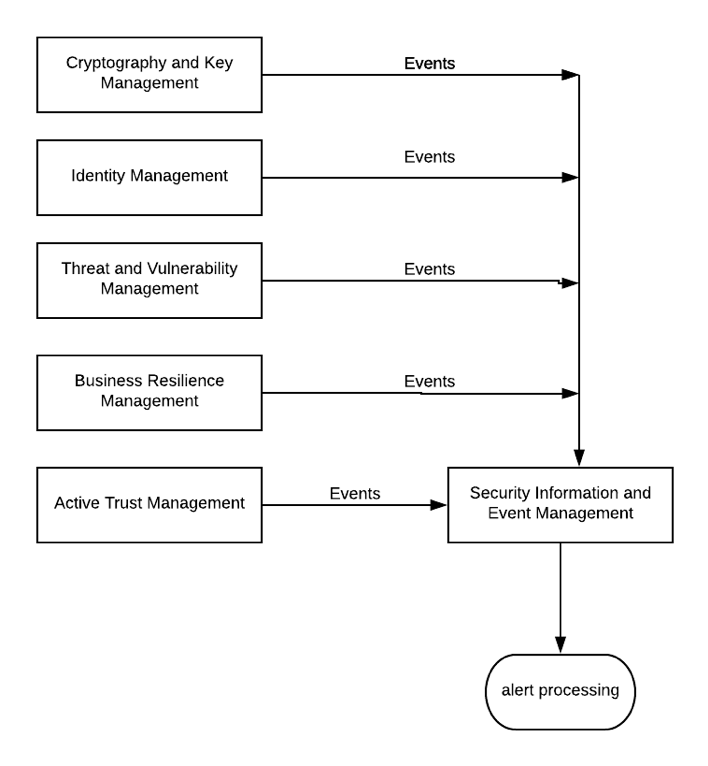
The logging capability is the bedrock of SecOps, and how it relates to other security capabilities can be simplified as in the diagram below. The boxes on the left are self-explanatory with the possible exception of Active Trust Management – this is heavily network-oriented and at the engineering end of the rainbow, its about firewalls, reverse and forward proxies mainly:
Custom Use Cases
For the vast majority of cases, custom use cases will need to be formulated. This involves building a picture of “normal”, so as to enable alerting on abnormal. So taking the networking example: what are my data flows? Take my most critical applications – what are source and destination IP addresses, and what is the port on the server-side of the client-server relationship? So then a possible custom use case could be: raise an alert when a connection is aimed at the server from anywhere other than the client(s).
Generic use cases are no-brainers. Examples are brute force attempts and technology or user behaviour-specific use cases. Some good examples are here. Custom use cases requires an understanding of how applications, networks, and operating systems are knitted together. But both custom and generic use cases require a log source to be called out. For network events, this will be a firewall as the best candidate. It generally makes very little sense to deploy network IDS nodes in cloud.
So for each application, generate a table of custom use cases, and identify a log source for each. Generic use cases are those configured auto-tragically in Splunk Enterprise Security for example. But even Splunk cannot magically give you custom use cases, or even ensure that all devices are included in the coverage for generic use cases. No – humans still have a monopoly over custom use cases and well, really, most of SIEM configuration. AI and Cyberdyne Systems won’t be able to get near custom use cases in our lifetimes, or ever, other than the fantasy world of vendor Powerpoint slides.
Don’t forget to test custom use case alerting. So for network events, spin up a VM in a centrally trusted area, like a management Vnet/VPC for example. Port scan from there to see if alerts are triggered. Netcat can be very useful here too, for spoofing source addresses for example.
Correlation
Correlation was the phrase used by vendors in the heady days of the 00s. The premise was something like this: event A, event B, and event C. Taken in isolation (topical), each seem innocuous. But bake them together and you have a clear indicator that skullduggery is afoot.
I suggest you park correlation in the early stage of a logging capability deployment. Maybe consider it for down the road, once a decent level of maturity has been reached in SecOps, and consider also that any attempt to try and get too clever can result in your SIEM frying circuit boards. The aim initially should be to reduce complexity as much as possible, and nothing is better at adding complexity than correlation. Really – basic alerting on generic and custom use cases gives you most of the coverage you need for now, and in any case, you can’t expect to get anywhere near an ideal state with logging.
SaaS
Operating system logs are important in many cases. When you decide to SaaS a solution, note that you lose control over operating system events. You cannot turn off events that you’re not interested in (e.g. Windows Object auditing events which have had a few too many pizzas). This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
Note – its also, in most cases, not such a great idea to use a SaaS based SIEM. Why? Because this function has connectivity with everything. It has trust relationships with dev/test, pre-prod, and production. You really want full control over this platform (i.e. be able to login with admin credentials and take control of the OS), especially as it hosts lots of information that would be very interesting for attackers, and is potentially the main target for attackers, because of the trust relationships I mentioned before.
So with SaaS, its probably not the case that you are missing critical events. You just get flooded. The same applies to 3rd party applications, but for custom, in-house developed applications, you still have control of course of the application layer.
Custom, In-house Developed Applications
You have your debugging stream and you have your application stream. You can assign critical levels to events in your code (these are the classic syslog severity levels). The application events stream is critical. From an application security perspective, many events are not immediately intuitively of interest, but by using knowledge of how hackers work in practice, security can offer some surprises here, pleasant or otherwise.
If you’re a developer, you can ease the strain on your infosec colleagues by using consistent JSON logging keys across the board. For example, don’t start with ‘userid’ and then flip to ‘user_id’ later, because it makes the configuration of alerting more of a challenge than it needs to be. To some extent, this is unavoidable, because different vendors use different keys, but every bit helps. Note also that if search patterns for alerting have to cater for multiple different keys in JSON documents, the load on the SIEM will be unnecessarily high.
It goes without saying also: think about where your application and debug logs are being transmitted and stored. These are a source of extremely valuable intelligence for an attacker.
The Technology
The technological side of the logging capability isn’t the biggest side. The technology is there to fulfil a logging requirement, it is not in itself the logging capability. There are also people and processes around logging, but its worth talking about the technology.
What’s more common than many would think – organisation acquires a COTS SIEM tool but the security engineers hate it. Its slow and doesn’t do much of any use. So they find their own way of aggregating network-centralised events with a syslog bucket of some description. Performance is very often the reason why engineers will be grep’ing over syslog text files.
Whereas the aforementioned sounds ineffective, sadly its more effective than botched SIEM deployments with poorly designed tech. It also ticks the “network centralised logging” box for auditors.
The open-source tools solution can work for lots of organisations, but what you don’t get so easily is the real-time alerting. The main cost will be storage. No license fees. Just take a step back, and think what it is you really want to achieve in logging (see the design process above). The features of the open source logging solution can be something like this:
Rsyslog is TCP and covers authentication of hosts. Rsyslog is a popular protocol because it enables TCP layer transmission from most log source types (one exception is some Cisco network devices and firewalls), and also encryption of data in transit, which is strongly recommended in a wide open, “flat” network architecture where eavesdropping is a prevalent risk.
Even Windows can “speak” rsyslog with the aid of a local agent such as nxlog.
There are plenty of Host-based Intrusion Detection System (HIDS) agents for Linux and Windows – OSSEC, Suricata, etc.
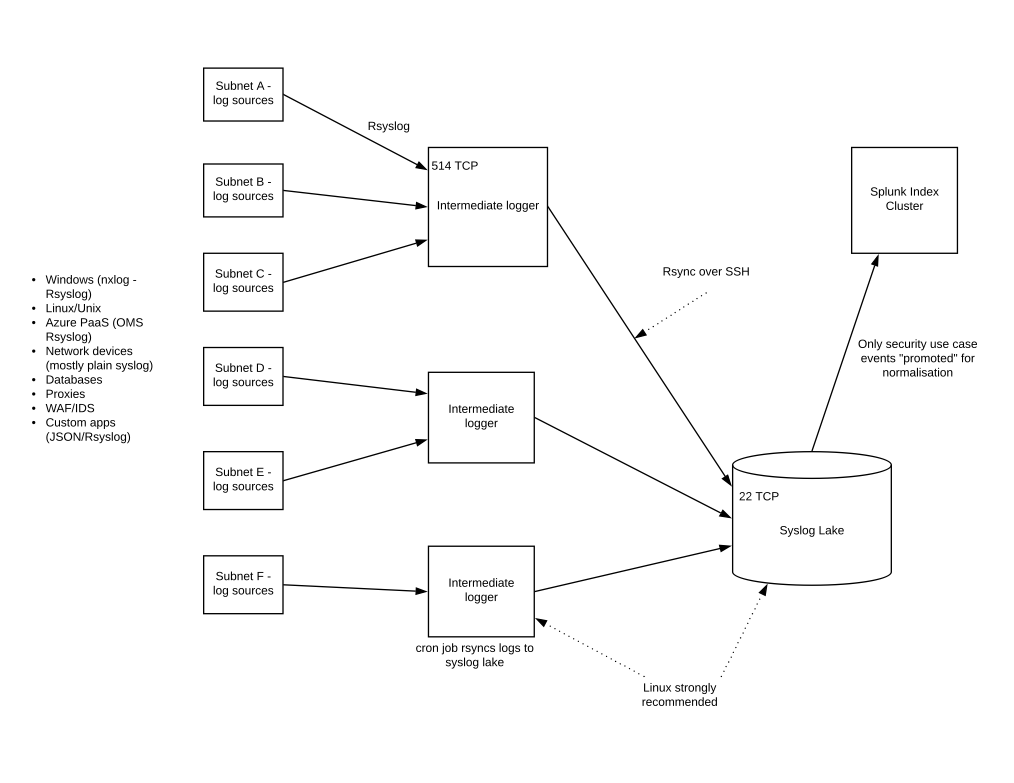
Intermediate network logging Rsyslog servers can aggregate logs for network zones/subnets. There are the equivalent of Splunk forwarders or Alienvault Sensors. A cron job runs an rsync over Secure Shell (SSH), which uploads the batches of events data periodically to a Syslog Lake, for want of a better phrase.
The folder structure on the Syslog server can reflect dates – years, months, days – and distinct files are named to indicate the log source or intermediate server.
Splunk sales people have a dart board with my picture on it. To be fair, the official Splunk line is that they want to help their customers save events indexing money because it benefits them in the longer term. And they’re right, this does work for Splunk and their customers. But many of the resellers are either lacking the skills to help, or they are just interested in a quick and dirty install. “Live for today, don’t worry about tomorrow”.
Splunk really is a Lamborghini, and the few times when i’ve been involved in bidding beauty parades for SIEM, Splunk often comes out cheaper believe it or not. Splunk was made for logging and was engineered as such. Some of the other SIEM engines are poorly coded and connect to a MySQL database for example, whereas Splunk has its own database effectively. The difference in performance is extraordinary. A Splunk search involving a complex regex with busy indexers and search heads takes a fraction of the time to complete, compared with a similar scenario from other tools on the same hardware.
Three main ways to reduce events indexing costs with Splunk:
Root out useless events. Windows is the main culprit here, in particular Auditing of Objects. Do you need, for example, all that performance monitoring data? Debug events? Firewall AND NIDS events? Denied AND accepted packets from firewalls?
You can be highly selective about which events are forwarded to the Splunk indexer. One conceptual model just to illustrate the point is given below:
Threat Hunting
Threat Hunting is kind of the sexy offering for the world of defence. Offence has had more than its fair share of glamour offerings over the years. Now its defence’s turn. Or is it? I mean i get it. It’s a good thing to put on your profile, and in some cases there are dramatic lines such as “be the hunter or the hunted”.
However, a rational view of “hunting” is that it requires LOTS of resources and LOTS of skill – two commodities that are very scarce. Threat hunting in most cases is the worst kind of resources sink hole. If you take vulnerability management (TVM) and the kind of basic detection discussed thus far in this article, you have a defence capability that in most cases fits the risk management needs of the organisation. So then there’s two questions to ask:
How much does threat hunting offer on top of a suitably configured logging and TVM capability? Not much in the best of cases. Especially with credentialed scanning with TVM – there is very little of your attack surface that you cannot cover.
How much does threat hunting offer in isolation (i.e. threat hunting with no TVM or logging)? This is the worst case scenario that will end up getting us all fired in security. Don’t do it!!! Just don’t. You will be wide open to attack. This is similar to a TVM program that consists only of one-week penetration tests every 6 months.
Threat Intelligence (TI)
Ok so here’s a funny story. At a trading house client here in London around 2016: they were paying a large yellow vendor lots of fazools every month for “threat intelligence”. I couldn’t help but notice a similarity in the output displayed in the portal as compared with what i had seen from the client’s Alienvault. There is a good reason for this: it WAS Alienvault. The feeds were coming from switches and firewalls inside the client network, and clearly $VENDOR was using Alienvault also. So they were paying heaps to see a duplication of the data they already had in their own Alienvault.
The aforementioned is an extremely bad case of course. The worst of the worst. But can you expect more value from other threat intelligence feeds? Well…remember what i was saying about the value of an effective TVM and detection program? Ok I’ll summarise the two main problems with TI:
You can really achieve LOTS in defence with a good credentialed TVM program plus even a half-decent logging program. I speak as someone who has lots of experience in unrestricted penetration testing – believe me you are well covered with a good TVM and detection SecOps function. You don’t need to be looking at threats apart from a few caveats…see later.
TI from commercial feeds isn’t about your network. Its about the whole planet. Its like picking up a newspaper to find out what’s happening in the world, and seeing on the front cover that a butterfly in China has flapped its wings recently.
Where TI can be useful – macro developments and sector-specific developments. For example, a new approach to Phishing, or a new class of vulnerability with software that you host, or if you’re in the public sector and your friendly national spy agency has picked up on hostile intentions towards you. But i don’t want to know that a new malware payload has been doing the rounds. In the time taken to read the briefing, 2000 new payloads have been released to the wild.
Summary
Start out with a design process that takes input feeds from compliance and risk (perhaps threat modelling), use the resulting requirements to drive the LLD, which may or may not result in a decision to procure tech that meets the requirements of the LLD.
An effective logging capability can only be designed with intimate knowledge of the estate – databases, crown jewels, data flows – for each application. Without such knowledge, it isn’t possible to build even a barely useful logging capability. Call out your generic and custom use cases in your LLD, independent of technology.
Get your basic alerting first, correlation can come later, if ever.
Outsourcing is a waste of resources for second level SecOps.
With SaaS, your SIEM itself is dangerously exposed, and you have no control over what is logged from SaaS log sources.
You are not mandated to get a COTS. Think about what it is that you want to achieve. It could be that open source tools across the board work for you.
Splunk really is the Lamborghini of SIEMs and the “expensive” tag is unjustified. If you carefully design custom and generic use cases, and remove everything else from indexing, you suddenly don’t have such an expensive logger. You can also aggregate everything in a Syslog pool before it hits Splunk indexers, and be more selective about what gets forwarded.
I speak as someone with lots of experience in unrestricted penetration testing: Threat Hunting and Threat Intelligence aren’t worth the effort in most cases.
How many Security Analysts does it take to change a light bulb? The answer should be one but it seems organisations are insistent on spending huge amounts of money on armies of Analysts with very niche “skills”, as opposed to 6 (yes, 6!) Analysts with certain core skills groups whose abilities complement each other. Banks and telcos with 300 security professionals could reduce that number to 6.
Let me ask you something: is Symantec Control Compliance Suite (CCS) a “skill” or a product or both? Is Vulnerability Management a skill? Its certainly not a product. Is HP Tippingpoint IPS a product or a skill?
Is McAfee Vulnerability Manager 7.5 a skill whereas the previous version is another skill? So if a person has experience with 7.5, they are not qualified to apply for a shop where the previous version is used? Ok this is taking it to the extreme, but i dare say there have been cases where this analogy is applicable.
How long does it take a person to get “skilled up” with HP Arcsight SIEM? I was told by a respected professional who runs his own practice that the answer is 6 months. My immediate thought is not printable here. Sorry – 6 months is ridiculous.
So let me ask again, is Symantec CCS a skill? No – its a product. Its not a skill. If you take a person who has experience in operational/technical Vulnerability Management – you know, vulnerability assessment followed by the treatment of risk, then they will laugh at the idea that CCS is a skill. Its only a skill to someone who has never seen a command shell before, tested manually for a false positive, or taken part in an unrestricted manual network penetration test.
Being a software product from a major vendor means the GUI has been designed to make the software intuitive to use. I know that in vulnerability assessment, i need to supply the tool with IP addresses of targets and i need to tell the tool which tests I want to run against those targets. Maybe the area where I supply the addresses of targets is the tab which has “targets” written on it? And I don’t want to configure the same test every time I run it, maybe this “templates” tab might be able to help me? Do i need a $4000 2-week training course and a nice certificate to prove to the world that I can work effectively with such a product? Or should there be an effective accreditation program which certifies core competencies (including evidence of the ability to adapt fast to new tools) in security? I think the answer is clear.
A product such as a Vulnerability Management product is only a “Window” to a Vulnerability Management solution. Its only a GUI. It has been tailored to be intuitive to use. Its the thin layer on top of the Vulnerability Management solution. The solution itself is much bigger than this. The product only generates list of vulnerabilities. Its how the organisation treats those vulnerabilities that is key – and the product does not help too much with the bigger picture.
Historically vulnerability management has been around for years. Then came along commercial products, which basically just slapped a GUI on processes and practices that existed for 20 years+, after which the jobs market decided to call the product the solution. The product is the skill now, whereas its really vulnerability management that is the skill.
The ability to adapt fast to new tools is a skill in itself but it also is a skill that should be built-in by default: a skill that should be inherent with all professionals who enter the field. Flexibility is the key.
The real skills are those associated with areas for large volumes of intellectual capital. These are core technologies. Say a person has 5 years+ experience of working in Unix environments as a system administrator and has shown interest in scripting. Then they learn some aspects of network penetration testing and are also not afraid of other technologies (such as Windows). I can guarantee that they will be up and running in less than one day with any new Vulnerability Management tool, or SIEM tool, or [insert marketing buzzphrase here] that vendors can magic up.
Different SIEM tools use different terms and phrases for the same basic idea. HP uses “flex connectors” whilst Splunk talks about “Forwarders” and “Heavy Forwarders” and so on. But guess what? I understand English but If i don’t know what the words mean, i can check in an online dictionary. I know what a SIEM is designed to do and i get the data flows and architecture concept. Network aggregation of syslog and Windows Events is not an alien concept to me, and neither are all layers of the TCP/IP stack (a really basic requirement for all Analysts – or should be). Therefore i can adapt very easily to new tools in this space.
IPS/IDS and Firewalls? Well they’re not even very functional devices. If you have ever setup Snort or iptables you’ll be fine with whatever product is out there. Recently myself and another Consultant were asked to configure a Tippingpoint device. We were up and running in 10 minutes. There were a few small items that we needed to check against the product documentation. I have 15 years+ experience in the field but the other guy is new. Nonetheless he had configured another IPS product before. He was immediately up and running with the product – no problem. Of course what to configure in the rule base – that is a bigger story and it requires knowledge of threats, attack techniques and vulnerabilities – but that area is GENERIC to security – its not specific to a product.
I’ve seen some truly crazy job specifications. One i saw was Websense Specialist!! Come on – its a web proxy! Its Squid with extra cosmetic functions. The position would be filled by a Websense “Olympian” probably. But what sort of job is that? Carpe Diem my friends, Carpe Diem.
If you run a security consultancy and you follow the usual market game of micro-boxed, pigeon-holed security skills, i don’t know how you can survive. A requirement comes up for a project that involves a number of different products. Your existing consultants don’t have those products written anywhere on their CVs, so you go to market looking for contractors at 600 USD per day. You either find the people somehow, or you turn the project down. Either way you lose out massively. Or – you could have a base of 6 (its that number again) consultants with core skills that complement each other.
If the over-specialisation issue were addressed, businesses would save considerably on human resource and also find it easier to attract the right people. Pigeon-holed jobs are boring. It is possible and advisable to acquire human resource able to cover more bases in risk management.
So how many Security Analysts does it take to change a light bulb? The answer is 6, but typically in real life the number is the mark of the beast: 666.


 This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.