
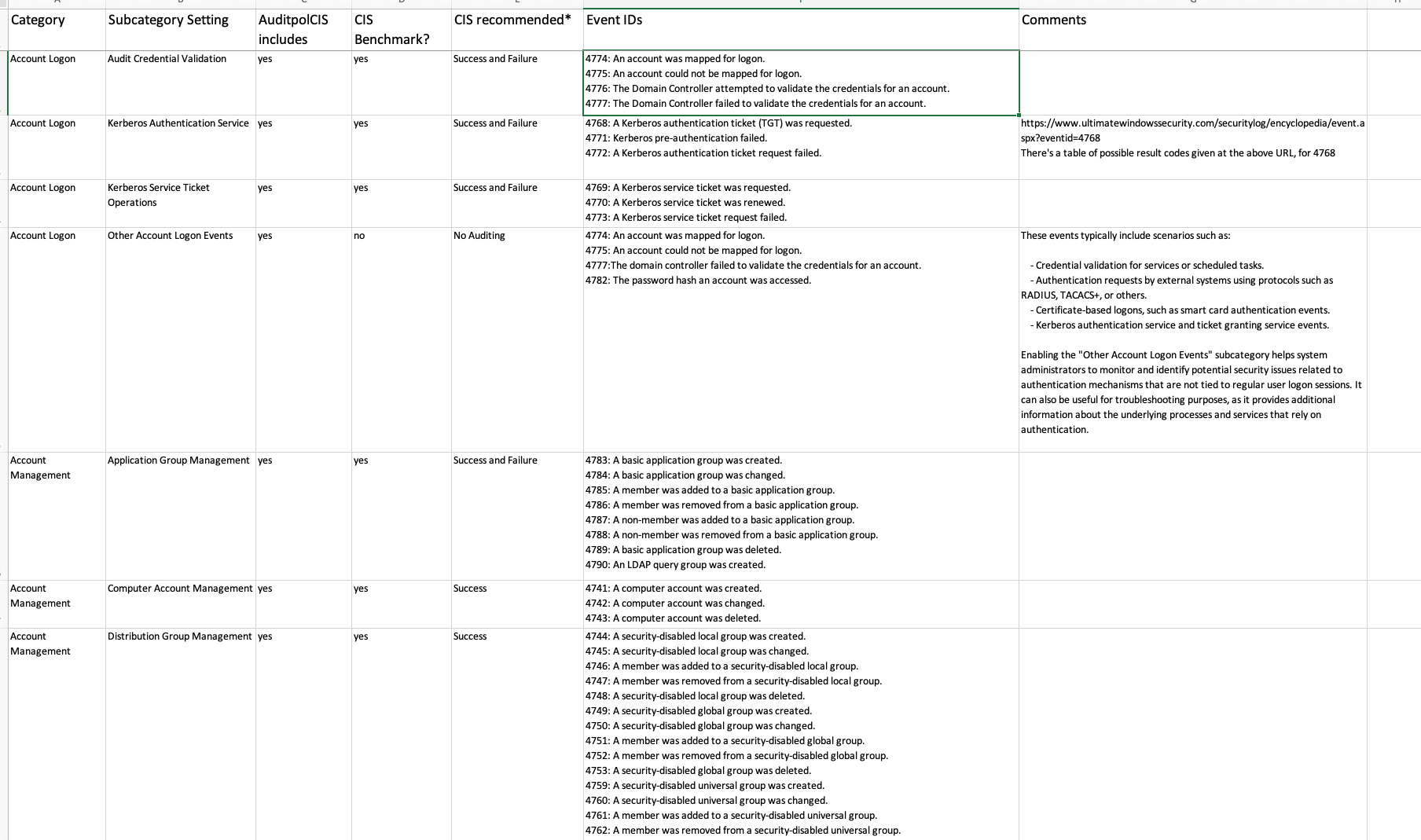
In our 2021 blog post, we focused on identifying quick wins for optimizing Windows Events, and provided a free spreadsheet (really free, not even a regwall) that indicated Windows Events that could be safely ignored, some of which cost lots for SIEM engines to ingest. This post takes a broader Windows Audit Policy view, and offers another free resource – this time taking a broader look in the context of comparing your setup for Windows Audit Policy, and the venerable CIS Benchmark for Windows 2019 Server.
If there’s sufficient interest i’ll follow up with a development effort for a Python tool (also freely available, on Github) that connects to your Windows server and performs the CIS Benchmark assessment as indicated in the spreadsheet.
SIEM Nightmares

Based on many first hand observations and second hand accounts, it’s not a stretch to say that many organisations are suffering from SIEM configuration issues, for which the result is a low signal-to-noise ratio. Your SIEM is ingesting lots of events, many of which are not at all helpful, and with most vendors charging by volume, it gets expensive. At the same time, the false negative problem is all too common. Forensics investigations reveal all too often that there are no events recorded by the expensive SIEM, that even closely relate to the incident. I hope you are never in this scenario. The short-term impact is never good.
Taking SIEM as a capability, if one is to advise on how to improve things, it is rarely ever about the technology. When one asks Analysts (and based on job postings, also hiring managers) about SIEM, it’s clear the first thing that comes to mind is Splunk. ELK, Sentinel, etc. I would estimate the technology-only focus with SIEM to be the norm rather than the exception, and it comes hand-in-hand with a failure to detect privilege elevations, and lateral movements for example.
There are some advisories that we can give out that are independent of your architecture, but many questions about SIEM configuration can only be answered by you, using your knowledge of the IT landscape in your organisation. The advisories in the referenced spreadsheet cover the “noise” part of the signal-to-noise ratio. These are events that are sure to be noise to at least a 90% level of assurance, from a security perspective.
Addtional Context on the Spreadsheet
Some context around the spreadsheet: where there is a CIS Benchmark metric for a specific Audit Subcategory, the spreadsheet follows exactly the CIS recommended setting. But there are some (e.g. DS Access –> Directory Service Access) where this subcategory was not covered by CIS. In these cases, an assessment is made based on our real-experience observations of logging volumes, versus the security (not the IT diagnostic, or other value) value of Audit Subcategories. In this case of the Directory Service Access subcategory, it can be turned off from a security perspective.
There is limited information available regarding actual experiences with specific event ID volumes. In 2018, I had the opportunity to track Windows events in a Splunk architecture for a government department. During this time, I recorded the occurrences of events over a 24-hour period on a network of approximately 150 Windows servers of various versions, some of which were quite exotic. This information has been valuable in supporting decisions related to whether or not to disable auditing.
SIEM Forwarder Filtering
There is another option offered by some SIEM vendors and that is to filter events by Event ID. Overall, the more resource-friendly approach is to prevent the events being generated at source, but in many cases this may not be feasible. Splunk for example allows you to filter at forwarders (via the inputs.conf file on the Splunk forwarder. This file is usually located in the $SPLUNK_HOME/etc/system/local/ directory … more info – BTW it looks like Splunk agrees with us on the 4662 event mentioned as an example above. Yay!).
Credits and Disclaimers
Windows Events are sometimes tricky to understand, both with respect of what the developers intended with those events, and the conditions under which they are generated. Sometimes with Windows Events, we are completely in unknown territory, even if there is some Microsoft documentation that covers them. Here’s one example from Microsoft documentation to fill us with confidence – “This auditing subcategory should not have any events in it, but for some reason Success auditing will enable the generation of event 4985″.
Ultimately only you can decide what’s best for the health of your SOC/SIEM. Only you know your network and your applications. The document supplied here was only intended as a guide, and to aid decision making. It was not intended to make decisions for you.
The cybersecurity landscape often focuses on the more sensational aspects, such as high-profile hacks or fake influencers, which can overshadow the essential work done by countless professionals in the background. These unsung heroes are dedicated to ensuring the stability and security of our digital infrastructure, and their contributions should not be underestimated. Among those are tthe likes of Randy Franklin Smith (founder of Ultmate Windows Security) who has put together an “encyclopedia” of Windows Event IDs. The experiences shared there were used in-part to form a view on whether or not to reject or accept certain Windows Events.
