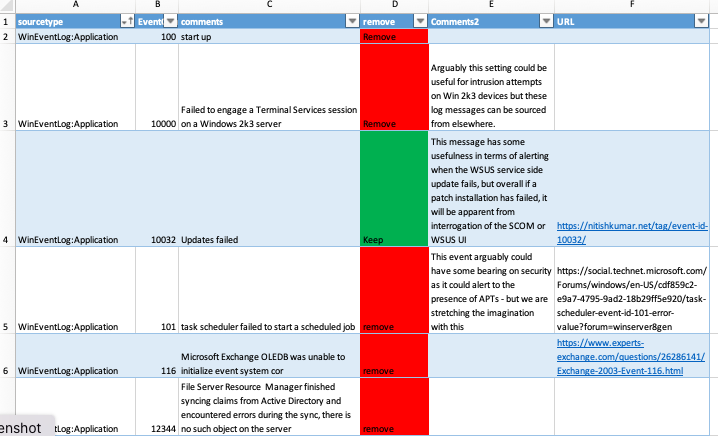
There has been a modicum of interest in a Windows spreadsheet I shared on social media recently, that if absorbed and acted upon, can be a early no-brainer win with SIEM products that are licensed based on volume or Events Per Second (EPS).
Its no big secret that Windows machines, virtual or real, are noisy. Clients I worked with – I would estimate 90%, for various reasonsdon’t act on the noise from Windows devices and it’s costing them a fortune (right or wrong, approx 50% of those prioritise other tasks).
In Splunk, one can use searches to estimate the benefit of removing noisy Windows events, and what I found was quite a broad range of results. It makes little sense to give the full breakdown because the result depends heavily on the spread and amount of Windows to other Operating Systems (OS). But there were a couple of cases where logging events volume was reduced by 70%.
Some points to note:
If the “remove” events are removed, Windows devices become very quiet. Some organisations use events as an indicator of “alive” rather than using active host monitoring. So with this logging configuration, an alternative (more sensible) host monitoring method is needed.
Removing these events is highly unlikely to ever result in a failure to detect an attack, but being 100% certain of this is impossible.
The most critical aspect of logging isn’t related to these events at all, its about your custom use cases. An example: a usual scenario is for a database listening service to accept application level connections on its listening service port (e.g. 1521 TCP is default for Oracle DB), and the source will be a web or middleware tier. So – configure an alert for when connections come from a source other than the middleware/application tier.
Very little actual analysis of Windows events and their purpose is known, or if it is known it is certainly not shared anywhere. There are some historical aspects to many of these events in that they’ve been around for more than 20 years but were never documented particualrly well, apart from here. I have added some insight but not for all events. Hence: if anyone would like any of the contents added or edited, feel free to comment below.
The context here is security. For other logging use cases, other events may need to be switched on.
The major versions of MS Windows Server that this journal applies to are: 2003, 2008, 2012. Many will apply to both 2016 and 2019.
So here are the links.. note there is no reg or pay wall. You will not be tracked and no data will be held about you. This is a completely free resource for you to collect anonymously:
Part Five – Cryptography and Key Management, and Identity Management
Part Six – Trust (network controls, such as firewalls and proxies), and Resilience
Logging
Notice “Logging” is used here, not “SIEM”. With use of “SIEM”, there is often a mental leap, or stumble, towards a commercial solution. But there doesn’t necessarily need to be a commercial solution. This post invites the reader to take a step back from the precipice of engaging with vendors, and check first if that journey is one you want to make.
Unfortunately, in 2020, it is still the case that many fintechs are doing one of two things:
Procuring a commercial solution without thinking about what is going to be logged, or thinking about the actual business goals that a logging solution is intended to achieve.
Just going with the Cloud Service Provider’s (CSP) SaaS offering – e.g. Stackdriver (now called “Operations”) for Google Cloud, or Security Center for Azure.
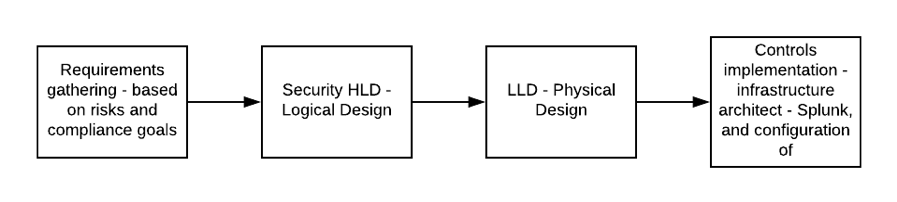
Design Process
The process HLD takes into risks from threat modelling (and maybe other sources), and another input from compliance requirements (maybe security standards and legal requirements), and uses the requirements from the HLD to drive the LLD. The LLD will call out the use cases and volume requirements that satisfy the HLD requirements – but importantly, it does not cover the technological solution. That comes later.
The diagram above calls out Splunk but of course it doesn’t have to be Splunk.
Security Operations
The end goal of the design process is heavily weighted towards a security operations or protective monitoring capability. Alerts will be specified which will then be configured into the technological solution (if it supports this). Run-books are developed based on on-going continuous improvement – this “tuning” is based on adjusting to false positives mainly, and adding further alerts, or modifying existing alerts.
The decision making on how to respond to alerts requires intimate knowledge of networks and applications, trust relationships, data flows, and the business criticality of information assets. This is not a role for fresh graduates. Risk assessment drives the response to an alert, and the decision on whether or not to engage an incident response process.
General IT monitoring can form the first level response, and then Security Operations consumes events from this first level that are related to potential security incidents.
Two main points relating this SecOps function:
Outsourcing doesn’t typically work when it comes to the 2nd level. Outsourcing of the first level is more likely to be cost effective. Dr Anton Chuvakin’s post on what can, and cannot be outsourced in security is the most well-rounded and realistic that i’ve seen. Generally anything that requires in-house knowledge and intimacy of how events relate to business risks – this cannot be outsourced at all effectively.
The maturity of SecOps doesn’t happen overnight. Expect it to take more than 12 months for a larger fintech with a complex cloud footprint.
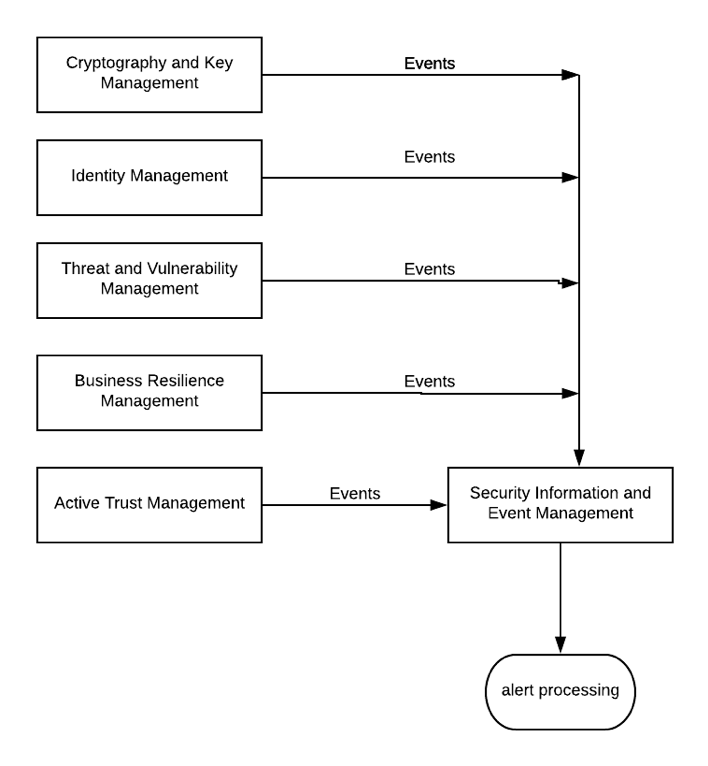
The logging capability is the bedrock of SecOps, and how it relates to other security capabilities can be simplified as in the diagram below. The boxes on the left are self-explanatory with the possible exception of Active Trust Management – this is heavily network-oriented and at the engineering end of the rainbow, its about firewalls, reverse and forward proxies mainly:
Custom Use Cases
For the vast majority of cases, custom use cases will need to be formulated. This involves building a picture of “normal”, so as to enable alerting on abnormal. So taking the networking example: what are my data flows? Take my most critical applications – what are source and destination IP addresses, and what is the port on the server-side of the client-server relationship? So then a possible custom use case could be: raise an alert when a connection is aimed at the server from anywhere other than the client(s).
Generic use cases are no-brainers. Examples are brute force attempts and technology or user behaviour-specific use cases. Some good examples are here. Custom use cases requires an understanding of how applications, networks, and operating systems are knitted together. But both custom and generic use cases require a log source to be called out. For network events, this will be a firewall as the best candidate. It generally makes very little sense to deploy network IDS nodes in cloud.
So for each application, generate a table of custom use cases, and identify a log source for each. Generic use cases are those configured auto-tragically in Splunk Enterprise Security for example. But even Splunk cannot magically give you custom use cases, or even ensure that all devices are included in the coverage for generic use cases. No – humans still have a monopoly over custom use cases and well, really, most of SIEM configuration. AI and Cyberdyne Systems won’t be able to get near custom use cases in our lifetimes, or ever, other than the fantasy world of vendor Powerpoint slides.
Don’t forget to test custom use case alerting. So for network events, spin up a VM in a centrally trusted area, like a management Vnet/VPC for example. Port scan from there to see if alerts are triggered. Netcat can be very useful here too, for spoofing source addresses for example.
Correlation
Correlation was the phrase used by vendors in the heady days of the 00s. The premise was something like this: event A, event B, and event C. Taken in isolation (topical), each seem innocuous. But bake them together and you have a clear indicator that skullduggery is afoot.
I suggest you park correlation in the early stage of a logging capability deployment. Maybe consider it for down the road, once a decent level of maturity has been reached in SecOps, and consider also that any attempt to try and get too clever can result in your SIEM frying circuit boards. The aim initially should be to reduce complexity as much as possible, and nothing is better at adding complexity than correlation. Really – basic alerting on generic and custom use cases gives you most of the coverage you need for now, and in any case, you can’t expect to get anywhere near an ideal state with logging.
SaaS
Operating system logs are important in many cases. When you decide to SaaS a solution, note that you lose control over operating system events. You cannot turn off events that you’re not interested in (e.g. Windows Object auditing events which have had a few too many pizzas). This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
Note – its also, in most cases, not such a great idea to use a SaaS based SIEM. Why? Because this function has connectivity with everything. It has trust relationships with dev/test, pre-prod, and production. You really want full control over this platform (i.e. be able to login with admin credentials and take control of the OS), especially as it hosts lots of information that would be very interesting for attackers, and is potentially the main target for attackers, because of the trust relationships I mentioned before.
So with SaaS, its probably not the case that you are missing critical events. You just get flooded. The same applies to 3rd party applications, but for custom, in-house developed applications, you still have control of course of the application layer.
Custom, In-house Developed Applications
You have your debugging stream and you have your application stream. You can assign critical levels to events in your code (these are the classic syslog severity levels). The application events stream is critical. From an application security perspective, many events are not immediately intuitively of interest, but by using knowledge of how hackers work in practice, security can offer some surprises here, pleasant or otherwise.
If you’re a developer, you can ease the strain on your infosec colleagues by using consistent JSON logging keys across the board. For example, don’t start with ‘userid’ and then flip to ‘user_id’ later, because it makes the configuration of alerting more of a challenge than it needs to be. To some extent, this is unavoidable, because different vendors use different keys, but every bit helps. Note also that if search patterns for alerting have to cater for multiple different keys in JSON documents, the load on the SIEM will be unnecessarily high.
It goes without saying also: think about where your application and debug logs are being transmitted and stored. These are a source of extremely valuable intelligence for an attacker.
The Technology
The technological side of the logging capability isn’t the biggest side. The technology is there to fulfil a logging requirement, it is not in itself the logging capability. There are also people and processes around logging, but its worth talking about the technology.
What’s more common than many would think – organisation acquires a COTS SIEM tool but the security engineers hate it. Its slow and doesn’t do much of any use. So they find their own way of aggregating network-centralised events with a syslog bucket of some description. Performance is very often the reason why engineers will be grep’ing over syslog text files.
Whereas the aforementioned sounds ineffective, sadly its more effective than botched SIEM deployments with poorly designed tech. It also ticks the “network centralised logging” box for auditors.
The open-source tools solution can work for lots of organisations, but what you don’t get so easily is the real-time alerting. The main cost will be storage. No license fees. Just take a step back, and think what it is you really want to achieve in logging (see the design process above). The features of the open source logging solution can be something like this:
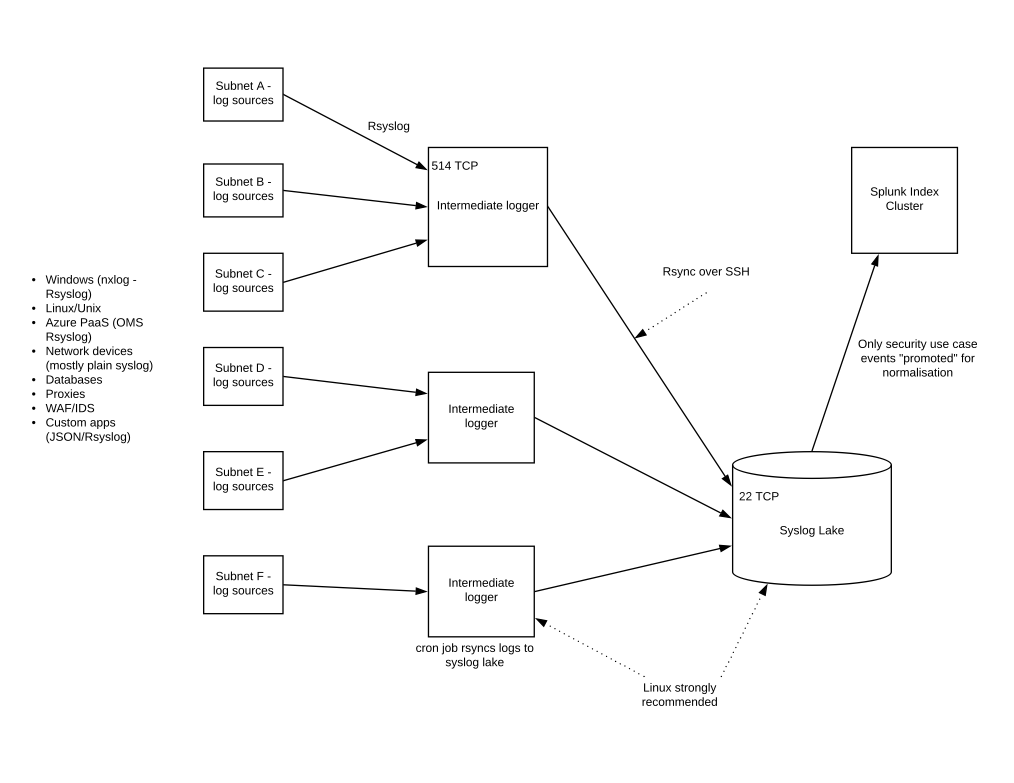
Rsyslog is TCP and covers authentication of hosts. Rsyslog is a popular protocol because it enables TCP layer transmission from most log source types (one exception is some Cisco network devices and firewalls), and also encryption of data in transit, which is strongly recommended in a wide open, “flat” network architecture where eavesdropping is a prevalent risk.
Even Windows can “speak” rsyslog with the aid of a local agent such as nxlog.
There are plenty of Host-based Intrusion Detection System (HIDS) agents for Linux and Windows – OSSEC, Suricata, etc.
Intermediate network logging Rsyslog servers can aggregate logs for network zones/subnets. There are the equivalent of Splunk forwarders or Alienvault Sensors. A cron job runs an rsync over Secure Shell (SSH), which uploads the batches of events data periodically to a Syslog Lake, for want of a better phrase.
The folder structure on the Syslog server can reflect dates – years, months, days – and distinct files are named to indicate the log source or intermediate server.
Splunk sales people have a dart board with my picture on it. To be fair, the official Splunk line is that they want to help their customers save events indexing money because it benefits them in the longer term. And they’re right, this does work for Splunk and their customers. But many of the resellers are either lacking the skills to help, or they are just interested in a quick and dirty install. “Live for today, don’t worry about tomorrow”.
Splunk really is a Lamborghini, and the few times when i’ve been involved in bidding beauty parades for SIEM, Splunk often comes out cheaper believe it or not. Splunk was made for logging and was engineered as such. Some of the other SIEM engines are poorly coded and connect to a MySQL database for example, whereas Splunk has its own database effectively. The difference in performance is extraordinary. A Splunk search involving a complex regex with busy indexers and search heads takes a fraction of the time to complete, compared with a similar scenario from other tools on the same hardware.
Three main ways to reduce events indexing costs with Splunk:
Root out useless events. Windows is the main culprit here, in particular Auditing of Objects. Do you need, for example, all that performance monitoring data? Debug events? Firewall AND NIDS events? Denied AND accepted packets from firewalls?
You can be highly selective about which events are forwarded to the Splunk indexer. One conceptual model just to illustrate the point is given below:
Threat Hunting
Threat Hunting is kind of the sexy offering for the world of defence. Offence has had more than its fair share of glamour offerings over the years. Now its defence’s turn. Or is it? I mean i get it. It’s a good thing to put on your profile, and in some cases there are dramatic lines such as “be the hunter or the hunted”.
However, a rational view of “hunting” is that it requires LOTS of resources and LOTS of skill – two commodities that are very scarce. Threat hunting in most cases is the worst kind of resources sink hole. If you take vulnerability management (TVM) and the kind of basic detection discussed thus far in this article, you have a defence capability that in most cases fits the risk management needs of the organisation. So then there’s two questions to ask:
How much does threat hunting offer on top of a suitably configured logging and TVM capability? Not much in the best of cases. Especially with credentialed scanning with TVM – there is very little of your attack surface that you cannot cover.
How much does threat hunting offer in isolation (i.e. threat hunting with no TVM or logging)? This is the worst case scenario that will end up getting us all fired in security. Don’t do it!!! Just don’t. You will be wide open to attack. This is similar to a TVM program that consists only of one-week penetration tests every 6 months.
Threat Intelligence (TI)
Ok so here’s a funny story. At a trading house client here in London around 2016: they were paying a large yellow vendor lots of fazools every month for “threat intelligence”. I couldn’t help but notice a similarity in the output displayed in the portal as compared with what i had seen from the client’s Alienvault. There is a good reason for this: it WAS Alienvault. The feeds were coming from switches and firewalls inside the client network, and clearly $VENDOR was using Alienvault also. So they were paying heaps to see a duplication of the data they already had in their own Alienvault.
The aforementioned is an extremely bad case of course. The worst of the worst. But can you expect more value from other threat intelligence feeds? Well…remember what i was saying about the value of an effective TVM and detection program? Ok I’ll summarise the two main problems with TI:
You can really achieve LOTS in defence with a good credentialed TVM program plus even a half-decent logging program. I speak as someone who has lots of experience in unrestricted penetration testing – believe me you are well covered with a good TVM and detection SecOps function. You don’t need to be looking at threats apart from a few caveats…see later.
TI from commercial feeds isn’t about your network. Its about the whole planet. Its like picking up a newspaper to find out what’s happening in the world, and seeing on the front cover that a butterfly in China has flapped its wings recently.
Where TI can be useful – macro developments and sector-specific developments. For example, a new approach to Phishing, or a new class of vulnerability with software that you host, or if you’re in the public sector and your friendly national spy agency has picked up on hostile intentions towards you. But i don’t want to know that a new malware payload has been doing the rounds. In the time taken to read the briefing, 2000 new payloads have been released to the wild.
Summary
Start out with a design process that takes input feeds from compliance and risk (perhaps threat modelling), use the resulting requirements to drive the LLD, which may or may not result in a decision to procure tech that meets the requirements of the LLD.
An effective logging capability can only be designed with intimate knowledge of the estate – databases, crown jewels, data flows – for each application. Without such knowledge, it isn’t possible to build even a barely useful logging capability. Call out your generic and custom use cases in your LLD, independent of technology.
Get your basic alerting first, correlation can come later, if ever.
Outsourcing is a waste of resources for second level SecOps.
With SaaS, your SIEM itself is dangerously exposed, and you have no control over what is logged from SaaS log sources.
You are not mandated to get a COTS. Think about what it is that you want to achieve. It could be that open source tools across the board work for you.
Splunk really is the Lamborghini of SIEMs and the “expensive” tag is unjustified. If you carefully design custom and generic use cases, and remove everything else from indexing, you suddenly don’t have such an expensive logger. You can also aggregate everything in a Syslog pool before it hits Splunk indexers, and be more selective about what gets forwarded.
I speak as someone with lots of experience in unrestricted penetration testing: Threat Hunting and Threat Intelligence aren’t worth the effort in most cases.

 This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.
This can be a problem if you decide to go with a COTS where licensing costs are based on volume of events. Also, you cannot turn on OS events that you could be interested in. The way CSPs play here is to assume everything is interesting, which can get expensive. Very expensive.